Cache 机制
文章内容来自于《凤凰架构》,推荐阅读。
1 HTTP 客户端缓存
HTTP 设计之初就是确定客户端与服务端 “无状态” 的交互原则,所以不可避免地导致携带重复数据导致网络性能降低。对此,HTTP 协议的解决方案是客户端缓存。
在 HTTP 的演进中,形成了 “状态缓存” “强制缓存” “协商缓存” 的机制。
1.1 状态缓存
状态缓存 是指不通过服务器,客户端直接根据缓存的信息对目标网站判断。HTTP 301 永久重定向 就是状态缓存。
1.2 强制缓存
强制缓存 的基本原理很直接:一定时间内,请求的资源内容和状态不一定会改变,因此客户端可以无需发送请求,在时间内一直持有和使用该资源的本地缓存。
根据约定,强制缓存在浏览器的地址输入、页面链接跳转、新开窗口、前进和后退中均可以生效。但是,用户主动刷新页面时应当失效。
HTTP 协议有两类 Header 实现了强制缓存机制:Expires、Cache-Control。
1.2.1 Expires
Expires 的值为一个 Deadline,表示:当服务器回复时带有该 Header,意味着服务器承诺该资源在 Deadline 之间不会发生变动,客户端可以直接缓存并使用该回复。
|
|
Expires 是最初的 HTTP 缓存机制,其设计非常简单,但是无法处理缓存提前失效等问题。
1.2.2 Cache-Control
Cache-Control 语义比 Expires 更加丰富,两者同时存在时,规定必须以 Cache-Control 为准。
|
|
Cache-Control 在客户端请求 Header 或者服务端回复 Header 中都可以存在,其值可以为一系列参数:
-
max-age 和 s-maxage
max-age=<n> - 相对于请求时间 n 秒内,缓存是有效的。
s-maxage=<n> - “共享”缓存的有效时间,即允许被 CDN、代理等持有的缓存时间,由于提示 CDN 这类服务器缓存的有效事件。
-
public 和 private
指明资源是否设计用户私有资源。如果是 public,可以被代理、CDN 等缓存资源;如果是 private,只能有用户客户端进行缓存。
-
no-cache 和 no-store
no-cache 指该资源不应该被缓存,强制会话相同 URL 资源也必须请求获取,令强制缓存完全失效,但不影响协商缓存。
no-store 不强制会话中相同 URL 资源重复获取,但是禁止浏览器、CDN 等缓存资源。
-
no-transform
禁止以任何形式修改资源,不允许对 Content-Encoding、Content-Range、Content-Type 任何形式的修改。例如,禁止 CDN、代理自动压缩图片或文本。
-
min-fresh 和 only-if-cached
min-fresh=<n> - 建议服务器返回一个不少于 n 秒的缓存资源。
only-if-cached 表示服务器要求客户端必须使用缓存资源,如果缓存不能名字,则返回 503/Service Unvailable 错误。
-
must-revalidate 和 proxy-revalidate
must-revalidate 表示缓存资源过期后,一定要从服务器获取。
proxy-revalidate 与 must-revalidate 语义相同,专用于提示 CDN、代理。
1.3 协商缓存
强制缓存是基于时效性,客户端与服务端协商好缓存的时间,不需要进行检查判断缓存是否失效。协商缓存 是基于检查的缓存机制,每次请求会检查缓存是否失效,从而决定是使用缓存资源还是进行请求。
协商缓存检查变动存在两种方式:
- 基于资源的修改时间
- 基于资源的唯一标识
根据约定,协商缓存不仅仅在强制缓存的场景中有效,在用户主动刷新页面(F5)时也有效,只有用户强制刷新(Ctrl+F5)或明确禁用时才失效。
1.3.1 Last-Modified 和 If-Modified-Since
Last-Modified 是服务器回复的 Header,用户告知客户端资源的最后修改时间。当客户端再次需要请求该资源时,通过 If-Modified-Since 把收到的最后修改时间发送给服务器。
服务器收到该请求后,发现资源没有修改过,那么返回 304/Not Modified 回复,无须包含资源内容,表示让客户端使用缓存资源。
|
|
服务器收到该请求后,发现资源变动后,那么返回 200/OK 回复,并且包含完整的资源内容。
|
|
1.3.2 ETag 和 If-None-Match
Etag 是服务器回复的 Header,告诉客户端该资源的唯一标识。当客户端再次请求该资源时,会通过 If-None-Match 把收到的唯一标识发送回服务端。
服务器收到该请求后,发现资源的唯一标识与请求中的一致,那么返回 304/Not Modified 回复,无须包含资源内容,表示让客户端使用缓存资源。
|
|
服务器收到该请求后,发现资源唯一标识有变动,就返回 200/OK 与完成资源内容。
|
|
可以看到,ETag 通过判断资源唯一表示来判断资源是否变动过,其一致性比 Last-Modified 更高(可能资源修改过但是内容每发生变化,这样 Last-Modified 其实是失效的)。 但是,因为每次需要计算资源的唯一标识,因此其性能也是最差的。
1.4 多版本资源缓存
前面所说的都是针对于 “单个资源” 的缓存,但是一个 URL 可能对应着不同版本的资源。例如资源的不同语言版本,不同的编码方式(Content-Type)等。
对于一个 URL 能够获取多个资源的场景,缓存也需要明确的表示根据什么内容来缓存资源,使用 Vary Header。
|
|
以上回复就是告知客户端,根据 Accept 与 User-Agent 来缓存资源,不同 Accept 和 User-Agent 的组合缓存不同的资源。
2 CDN
内容分发网络(Content Distribution Network,CDN)是将客户端缓存、域名解析等综合运用的方式。CDN 的工作过程,主要涉及到路由解析、内容分发、负载均衡和 CDN 应用四个方面。
2.1 路由解析
CDN 将用户对某个域名的请求解析到 CDN 的服务器上处理,这个过程就是依靠 DNS 服务器实现的。
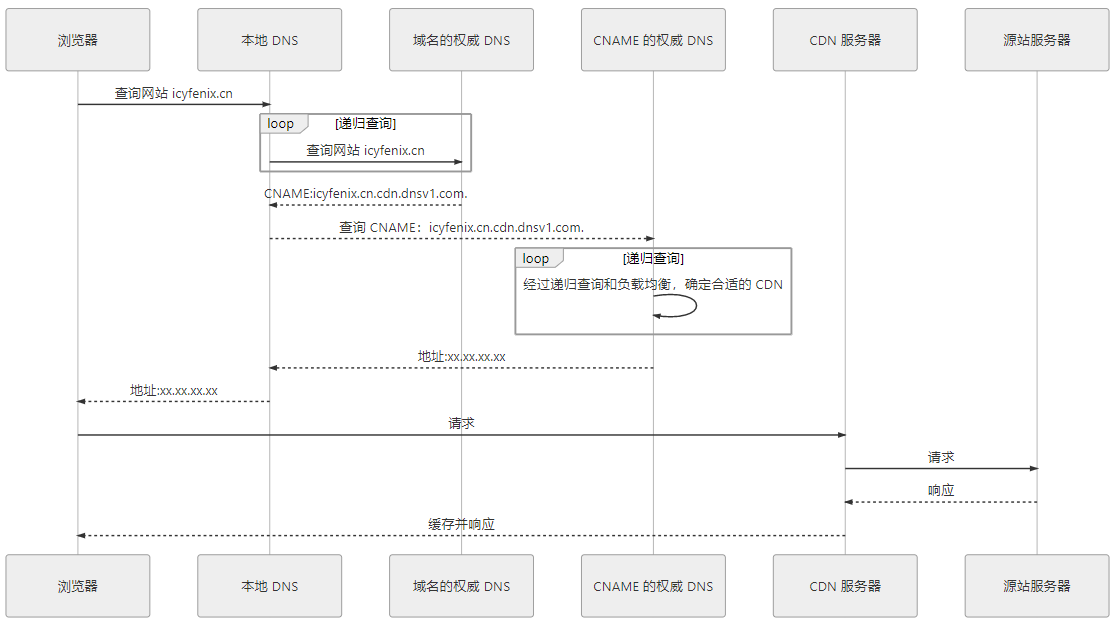
- 将你的域名(icyfenix.cn)在 CDN 服务器上注册为 “源站”,注册后就得到了一个 CNAME(icyfenix.cn.cdn.dnsv1.com)。
- 处理你的域名的 DNS 服务商上个将得到的 CNAME 注册为一条 CNAME 记录。
- 用户访问时,DNS 服务商解析出 CNAME 返回给本地 DNS。
- 本地 DNS 查询 CNAME,CDN 服务商的 DNS 服务器返回合适的 CDN 服务器 IP 地址。
- 用户访问 CDN 服务器。CDN 服务器如果没有缓存请求的资源,就会请求源站,并缓存。
2.2 内容分发
可以看到,CDN 服务器透明的接管了用户发出的访问资源,另一个问题就是 CDN 如何获得源站的资源。
CDN 获取源站资源的过程称为 “内容分发”。主要有两种分发方式:
-
主动分发(Push)- 分发由源站主动发起,将内容从源站提送到各个 CDN 缓存服务器上。
主动分发需要源站调用 CDN 服务的 API,因此对于源站不是透明的。
主动分发一般用于网站要预载大量资源的场景,例如大型活动前缓存网站的资源。
-
被动回源(Pull)- 被动回源指,当某个资源首次被请求时,CDN 服务器没有缓存该资源,那么就会立即从源站获取。
被动回源中,CDN 服务器相当于普通用户(但是网络特别的快)访问源站,因此对于源站也是透明的。
在 CDN 服务器缓存源站资源后,还需要考虑如何管理(更新)缓存的资源。这个问题目前没有统一的标准可言,目前最常见的做法是 “超时被动失效” 与 “手动主动失效” 相结合。
- 超时被动失效 - 缓存资源有一定的过期时间,超过时间后 CDN 在下次请求时重新回源一次。
- 手工主动失效 - CDN 服务商提供缓存失效/更新接口,由源站主动更新缓存资源。例如网站可以在更新时通过 CD 来自动调用接口实现缓存更新。
2.3 CDN 的应用
CDN 最初是为了快速分发静态资源设计的,而目前 CDN 能够做更多的事。
- 加速静态资源分发
- 安全防御:CDN 可以看做网站的堡垒机,源站可以只对 CDN 提供服务,由 CDN 为外界用户提供服务。这样攻击就不容易直接攻击源站。
- 协议升级:不少 CDN 提供商对阵 SSL 证书服务,这样就可以实现源站基于 HTTP 协议,而对外用户提供 HTTPS 协议。类似,也可以源站提供 HTTP/1.x 协议,CDN 对外提供 HTTP/2 或 HTTP/3 协议等等。
- 状态缓存:CDN 不仅可以缓存网站资源,还可以缓存源站的 HTTP Status。例如可以通过 CDN 缓存源站的 301/302 来让客户端直接跳转。
- 修改资源:CDN 可以在返回资源时修改资源的任意内容。例如可以对资源自动压缩并修改 Content-Encoding,以节省带宽。
- 访问控制:CDN 可以实现 IP 黑/白 名单的功能,根据 IP 来进行流量控制等。
- 注入功能:通过修改返回资源的内容,CDN 可以在不修改源站的情况下,为源站注入各种功能。
3 缓存风险
3.1 缓存穿透
查询的数据不存在,导致大量请求都直接请求了后端服务。
常见的原因有:
-
业务逻辑 - 查询的数据真正的不存在,所以每次都越过缓存查询后端服务,然后返回一个空值。
业务逻辑原因是不可避免的,只能尽量减少缓存穿透的频率。可以约定一定时间内对返回为空的 Key 进行缓存,使得一段时间内缓存最多被穿透一次。进一步,后端服务可以记录这些 Key,当对应 Key 资源存在后,主动清理掉缓存的 Key 记录。
-
恶意攻击 - 恶意请求一个不存在的数据,导致大量请求都越过缓存,以此攻击后端服务。
通常在缓存之前设置一个布隆过滤器解决。通过布隆过滤器来大致过滤出请求的 Key,过滤后连缓存都不需要查询。
3.2 缓存击穿
缓存中某些热点资源的缓存失效了(例如超时失效),而热点资源请求是大量的,最终导致短时间大量请求到达后端服务。理想情况下,应该只有第一个请求访问后端服务,并完成资源缓存,其他请求命中缓存。
通常办法:
-
加锁同步 - 以资源的 Key 为锁,只让第一个请求可以访问后端服务,其他请求采取阻塞或重试策略。可以理解为所有请求排队。
-
热点数据由代码管理 - 缓存击穿是由热点数据的缓存失效引起的,所以针对于热点数据的缓存,不采取自动失效的机制,而是后端服务有计划的更新、失效。
3.3 缓存雪崩
缓存击穿是针对于热点数据的缓存失效导致的。缓存雪崩指的是:短时间内大批数据一起失效,导致这些数据请求都访问后端服务。
常见的原因有:
-
一些公共数据的缓存有着相同的过期时间(例如资源是一起预热缓存的)
-
缓存服务重启了,导致资源重新缓存并且过期时间相同
对应的解决方法:
- 提高缓存系统的可用性,例如分布式缓存
- 启动多级缓存,这样每级缓存数据通常过期时间是不同的
- 缓存时间设置随机偏移
3.4 缓存污染
缓存污染指的是:缓存的数据与真实的数据不一致。
为了尽可能的提高缓存的一致性(不可能完成保证),尽可能遵循一些常见的设计模式。例如 Cache Aside 模式、Read/Write Through、Write Behind Caching 等。
-
Cache Aside 模式
- 读数据时,先读缓存。如果没有,再读数据源,并将数据缓存。
- 写数据时,先写数据源,然后使缓存失效(不是主动更新)。