总结系列的文章是自己的学习或使用后,对相关知识的一个总结,用于后续可以快速复习与回顾。
本文是对 Linux 存储架构中的 VFS 层的一个总结,基本内容来源于网络的学习,以及自己观摩了下源码。
1 VFS 整体模型
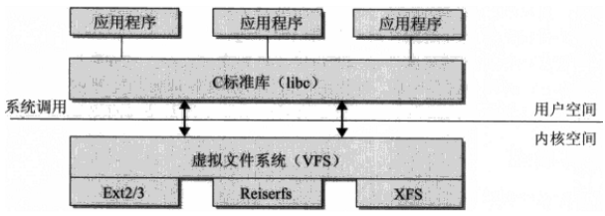
虚拟文件系统 是在用户进程与文件系统之间的一个抽象层,使得用户进程无需关系文件系统的实现,而通过相同的 IO 接口就可以进行数据的读写。

当用户程序对一个 fd 调用 IO 系统调用时,VFS 根据其对应的文件系统,调用其各个函数的实现。
可以将其想象问,你定义了一个 Golang interface VFS,而不同的文件系统实现了其 interface 的操作。上层只需要调用 VFS 的各个接口即可。
2 VFS 的通用文件模型
为了管理不同的文件系统,VFS 需要一个通用的文件模型来抽象整个文件系统的模型,而不同的文件系统需要通过自身的实现来满足这个模型。
VFS 的通用文件模型主要包含 4 个对象:
-
superblock:保存文件系统的基本元数据,一个文件系统有着一个 superblock 对象,包含文件系统类型、大小、状态等信息;
-
inode:保存一个文件或目录相关的元信息,代表着一个文件或目录,包含文件访问权限、文件类型、大小等(不包括文件名);
-
file:进程打开文件后,文件的表示,进程所看见的文件;
-
dentry:保存文件名(目录名)与其 inode 的对应关系,用于加速文件的查询;
2.1 inode
inode 是针对文件系统维度而言的,是每个文件或目录在文件系统的唯一标识,并包含其相关的元信息。可以想到,inode 需要持久化在具体的存储设备上,用以机器重启后恢复文件信息。
看一下 inode 的结构,可以知晓其对应的包含的信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
|
// fs.h
struct inode {
umode_t i_mode;
kuid_t i_uid;
kgid_t i_gid;
unsigned int i_flags;
const struct inode_operations *i_op;
struct super_block *i_sb;
struct address_space *i_mapping;
#ifdef CONFIG_SECURITY
void *i_security;
#endif
/* Stat data, not accessed from path walking */
unsigned long i_ino;
/*
* Filesystems may only read i_nlink directly. They shall use the
* following functions for modification:
*
* (set|clear|inc|drop)_nlink
* inode_(inc|dec)_link_count
*/
union {
const unsigned int i_nlink;
unsigned int __i_nlink;
};
dev_t i_rdev;
loff_t i_size;
struct timespec64 i_atime;
struct timespec64 i_mtime;
struct timespec64 i_ctime;
spinlock_t i_lock; /* i_blocks, i_bytes, maybe i_size */
unsigned short i_bytes;
u8 i_blkbits;
u8 i_write_hint;
blkcnt_t i_blocks;
#ifdef __NEED_I_SIZE_ORDERED
seqcount_t i_size_seqcount;
#endif
/* Misc */
unsigned long i_state;
struct rw_semaphore i_rwsem;
unsigned long dirtied_when; /* jiffies of first dirtying */
unsigned long dirtied_time_when;
struct hlist_node i_hash;
struct list_head i_io_list; /* backing dev IO list */
#ifdef CONFIG_CGROUP_WRITEBACK
struct bdi_writeback *i_wb; /* the associated cgroup wb */
/* foreign inode detection, see wbc_detach_inode() */
int i_wb_frn_winner;
u16 i_wb_frn_avg_time;
u16 i_wb_frn_history;
#endif
struct list_head i_lru; /* inode LRU list */
struct list_head i_sb_list;
struct list_head i_wb_list; /* backing dev writeback list */
union {
struct hlist_head i_dentry;
struct rcu_head i_rcu;
};
atomic64_t i_version;
atomic64_t i_sequence; /* see futex */
atomic_t i_count;
atomic_t i_dio_count;
atomic_t i_writecount;
#if defined(CONFIG_IMA) || defined(CONFIG_FILE_LOCKING)
atomic_t i_readcount; /* struct files open RO */
#endif
union {
const struct file_operations *i_fop; /* former ->i_op->default_file_ops */
void (*free_inode)(struct inode *);
};
struct file_lock_context *i_flctx;
struct address_space i_data;
struct list_head i_devices;
union {
struct pipe_inode_info *i_pipe;
struct block_device *i_bdev;
struct cdev *i_cdev;
char *i_link;
unsigned i_dir_seq;
};
__u32 i_generation;
void *i_private; /* fs or device private pointer */
} __randomize_layout;
|
- i_mode:文件类型,文件、目录等,也包括一些权限信息;
- i_uid、i_gid:文件所属的 UID 与 GID;
- i_flags:文件状态标记;
- i_op:inode 操作集合,不同的文件系统注册不同的操作;
- i_sb:指向所属文件系统的 superblock 结构;
- i_mapping:inode 对应的地址空间(address_space),对于 mmap 很重要;
- i_ino:inode 索引号;
- i_nlink:inode 引用计数;
- i_rdev:inode 表示设备文件时,为设备的 dev number(major+minor);
- i_size:inode 对应的文件大小;
- i_atime、i_mtime、i_ctime:文件最后访问时间、文件内容最后修改时间、inode 最后变化时间(权限、所有者等)
- i_bytes:文件占用存储设备的字节数(考虑稀疏文件);
- i_blocks:文件占用存储设备的块数(考虑稀疏文件);
- i_hash:inode 所存在的 hash 表;
- i_lru:inode 构成的 LRU list;
- i_fop:文件操作函数集合,不同文件系统不同实现;
从上面可以看到,任何文件系统上的每一个单元(普通文件、目录、设备、管道等等),在 VFS 都由一个 inode 来抽象。
因此,对于每个进程,所有的操作都是相同的,即基于文件系统某个“文件”的增删改查等等,接口是统一的。而各个文件系统就要实现自身的 i_op、i_fop 操作。
例如,对于网络 IO,也是通过 VFS 层操作的,而需要网络子系统实现一个走网络的 i_fop 操作。
2.1.1 文件系统对 inode 操作
看一下文件系统对 inode 的操作 inode_operations:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
// fs.h
struct inode_operations {
struct dentry * (*lookup) (struct inode *,struct dentry *, unsigned int);
const char * (*get_link) (struct dentry *, struct inode *, struct delayed_call *);
int (*permission) (struct inode *, int);
struct posix_acl * (*get_acl)(struct inode *, int);
int (*readlink) (struct dentry *, char __user *,int);
int (*create) (struct inode *,struct dentry *, umode_t, bool);
int (*link) (struct dentry *,struct inode *,struct dentry *);
int (*unlink) (struct inode *,struct dentry *);
int (*symlink) (struct inode *,struct dentry *,const char *);
int (*mkdir) (struct inode *,struct dentry *,umode_t);
int (*rmdir) (struct inode *,struct dentry *);
int (*mknod) (struct inode *,struct dentry *,umode_t,dev_t);
int (*rename) (struct inode *, struct dentry *,
struct inode *, struct dentry *, unsigned int);
int (*setattr) (struct dentry *, struct iattr *);
int (*getattr) (const struct path *, struct kstat *, u32, unsigned int);
ssize_t (*listxattr) (struct dentry *, char *, size_t);
int (*fiemap)(struct inode *, struct fiemap_extent_info *, u64 start,
u64 len);
int (*update_time)(struct inode *, struct timespec64 *, int);
int (*atomic_open)(struct inode *, struct dentry *,
struct file *, unsigned open_flag,
umode_t create_mode);
int (*tmpfile) (struct inode *, struct dentry *, umode_t);
int (*set_acl)(struct inode *, struct posix_acl *, int);
} ____cacheline_aligned;
|
大部分的函数功能看到其命名就可以知晓了,仅仅说明下部分函数:
lookup:根据 dentry(文件名)查找其 inode;link/unlink:用于将 dentry 绑定 inode,当引用计数为 0 时会删除文件;
i_op 都是对文件元信息的修改与查询,不涉及到对文件内容的修改。
2.1.1 文件系统对文件的操作
看一下文件系统对文件需要实现的操作 file_operations:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*read_iter) (struct kiocb *, struct iov_iter *);
ssize_t (*write_iter) (struct kiocb *, struct iov_iter *);
int (*iopoll)(struct kiocb *kiocb, bool spin);
int (*iterate) (struct file *, struct dir_context *);
int (*iterate_shared) (struct file *, struct dir_context *);
__poll_t (*poll) (struct file *, struct poll_table_struct *);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
unsigned long mmap_supported_flags;
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, loff_t, loff_t, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
int (*check_flags)(int);
int (*flock) (struct file *, int, struct file_lock *);
ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int);
ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int);
int (*setlease)(struct file *, long, struct file_lock **, void **);
long (*fallocate)(struct file *file, int mode, loff_t offset,
loff_t len);
void (*show_fdinfo)(struct seq_file *m, struct file *f);
#ifndef CONFIG_MMU
unsigned (*mmap_capabilities)(struct file *);
#endif
ssize_t (*copy_file_range)(struct file *, loff_t, struct file *,
loff_t, size_t, unsigned int);
loff_t (*remap_file_range)(struct file *file_in, loff_t pos_in,
struct file *file_out, loff_t pos_out,
loff_t len, unsigned int remap_flags);
int (*fadvise)(struct file *, loff_t, loff_t, int);
} __randomize_layout;
|
- read、write:读写文件操作,需要传入文件描述符(file)、缓冲区(存放返回数据)、读写大小、偏移量;
- read_iter、write_iter:异步 IO(aio)读写函数,通过结束后异步执行回调函数;
- mmap:将文件内容映射到进程的虚拟地址空间中;
- open:打开文件操作,这样讲一个 file 关联到了一个 inode;
- release:关闭文件操作,解绑 file 与 inode,使得可以清理一些数据;
- poll:IO 复用的文件系统实现,例如 select poll epoll;
- lock:锁定文件,用于多进程并发访问时进行同步;
- fallocate:进行文件内容的预分配,这与稀疏文件不同,会占用空间会实际展示在文件系统上;
2.2 superblock
superblock 包含一个具体文件系统的全局信息。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
struct super_block {
struct list_head s_list; /* Keep this first */
dev_t s_dev; /* search index; _not_ kdev_t */
unsigned char s_blocksize_bits;
unsigned long s_blocksize;
loff_t s_maxbytes; /* Max file size */
struct file_system_type *s_type;
const struct super_operations *s_op;
const struct dquot_operations *dq_op;
const struct quotactl_ops *s_qcop;
const struct export_operations *s_export_op;
unsigned long s_flags;
unsigned long s_iflags; /* internal SB_I_* flags */
unsigned long s_magic;
struct dentry *s_root;
struct rw_semaphore s_umount;
int s_count;
atomic_t s_active;
char s_id[32]; /* Informational name */
uuid_t s_uuid; /* UUID */
unsigned int s_max_links;
fmode_t s_mode;
const struct dentry_operations *s_d_op; /* default d_op for dentries */
/* s_inode_list_lock protects s_inodes */
spinlock_t s_inode_list_lock ____cacheline_aligned_in_smp;
struct list_head s_inodes; /* all inodes */
spinlock_t s_inode_wblist_lock;
struct list_head s_inodes_wb; /* writeback inodes */
} __randomize_layout;
|
- s_list :所有存在的文件系统以 list 方式组织;
- s_dev :文件系统对应的设备的 dev 编号;
- s_blocksize_bits、s_blocksize :
- s_maxbytes :可以创建的最大文件大小;
- s_type :文件系统类型;
- s_op :文件系统操作,包含 mount、umount 等操作的实现;
- dq_op :文件系统 quota 功能的实现;
- s_magic :文件系统 magic number,每类文件系统有着唯一的 magic number;
- s_root :root 目录,如果是存储文件系统的话;
- s_uuid :文件系统 UUID,每个文件系统有着单机唯一的 UUID;
- s_inodes :所有 inode 的组成的链表;
- s_inodes_wb :所有等待 writeback 的 inode 组成的链表;
2.3 file
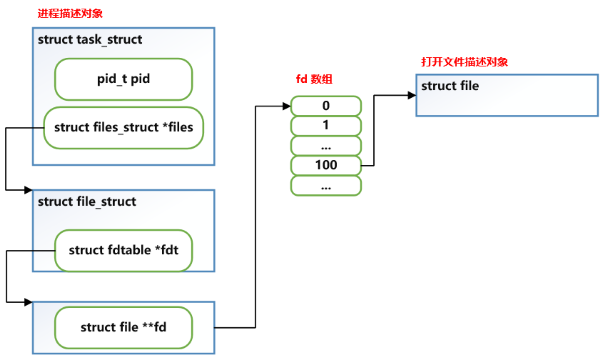
file 是文件在进程中的表示,当进程通过 open() 打开一个文件得到文件描述符后,内核就会有一个 file 对象来表示这个“打开”。
如下图所示,每个进程所打开的每个 fd,就对应这一个 file 结构对象。
看下具体的 file 对象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
// fs.h
struct file {
union {
struct llist_node fu_llist;
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path;
struct inode *f_inode; /* cached value */
const struct file_operations *f_op;
spinlock_t f_lock;
enum rw_hint f_write_hint;
atomic_long_t f_count;
unsigned int f_flags;
fmode_t f_mode;
struct mutex f_pos_lock;
loff_t f_pos;
struct fown_struct f_owner;
const struct cred *f_cred;
struct file_ra_state f_ra;
u64 f_version;
#ifdef CONFIG_SECURITY
void *f_security;
#endif
/* needed for tty driver, and maybe others */
void *private_data;
#ifdef CONFIG_EPOLL
/* Used by fs/eventpoll.c to link all the hooks to this file */
struct list_head f_ep_links;
struct list_head f_tfile_llink;
#endif /* #ifdef CONFIG_EPOLL */
struct address_space *f_mapping;
…
} __randomize_layout
__attribute__((aligned(4))); /* lest something weird decides that 2 is OK */
|
- f_owner 包含处理该文件的进程有关信息,例如进程的 pid;
- f_ra 表示预读相关的操作,包含预读文件数据的大小、预读的方式等;
- f_mode 为打开文件时传递的方式,例如 readonly rw 等模式;
- f_flags 为 open 系统调用时传递的额外的 flag 标志;
- f_path 用于维护两个信息:
- 文件名与 inode 之间的关联(dentry);
- 文件所在文件系统的信息(vfsmount);
- f_op 为对应 inode 的文件操作函数;
- f_mapping :指向文件对应的 inode 的地址空间映射,即 inode -> i_mapping;
file.f_path 属性包含文件对应的 dentry 对象,dentry 中包含着对应的 inode 指针,因此完成了 file -> inode 的映射。
2.4 dentry
dentry 表示的是一个文件名与其对应的 inode 的关系,dentry 组成的树型结构构建起了某个文件系统的目录树。
每个文件系统有着一个没有父 dentry 的根目录,被文件系统对应的 superblock 所引用。
必须要清楚,磁盘等持久化存储设备上并没有存储 dentry。dentry 树型结构的构建是在 VFS 读取目录、文件的数据后,对应创建并构建的。也就是说,dentry 是一个缓存结构,用于运行时构建出树型组织结构,来加速文件、目录的查找。
看下其主要的数据结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
// dcache.h
struct dentry {
/* RCU lookup touched fields */
unsigned int d_flags; /* protected by d_lock */
seqcount_spinlock_t d_seq; /* per dentry seqlock */
struct hlist_bl_node d_hash; /* lookup hash list */
struct dentry *d_parent; /* parent directory */
struct qstr d_name;
struct inode *d_inode; /* Where the name belongs to - NULL is
* negative */
unsigned char d_iname[DNAME_INLINE_LEN]; /* small names */
/* Ref lookup also touches following */
struct lockref d_lockref; /* per-dentry lock and refcount */
const struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
unsigned long d_time; /* used by d_revalidate */
void *d_fsdata; /* fs-specific data */
union {
struct list_head d_lru; /* LRU list */
wait_queue_head_t *d_wait; /* in-lookup ones only */
};
struct list_head d_child; /* child of parent list */
struct list_head d_subdirs; /* our children */
/*
* d_alias and d_rcu can share memory
*/
union {
struct hlist_node d_alias; /* inode alias list */
struct hlist_bl_node d_in_lookup_hash; /* only for in-lookup ones */
struct rcu_head d_rcu;
} d_u;
} __randomize_layout;
|
- d_parent:父目录的 dentry,根目录 dentry 指向自身;
d_name:文件名/目录名;d_inode:文件名对应文件/目录的 inode;- d_op:文件系统 dentry 操作的实现;
- d_sb:dentry 所属的文件系统的 superblock 结构;
- d_lockref:dentry 引用计数;
- d_alias:链表元素,不同 dentry 表示相同文件时,会通过链表链接所有 dentry。例如,使用硬链接将两个不同名称对应同一个文件时,会发生这种情况;
2.4.1 dentry 操作
dentry_operations 结构保存了指向特定文件系统对 dentry 需要实现的操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
// dcache.h
struct dentry_operations {
int (*d_revalidate)(struct dentry *, unsigned int);
int (*d_weak_revalidate)(struct dentry *, unsigned int);
int (*d_hash)(const struct dentry *, struct qstr *);
int (*d_compare)(const struct dentry *,
unsigned int, const char *, const struct qstr *);
int (*d_delete)(const struct dentry *);
int (*d_init)(struct dentry *);
void (*d_release)(struct dentry *);
void (*d_prune)(struct dentry *);
void (*d_iput)(struct dentry *, struct inode *);
char *(*d_dname)(struct dentry *, char *, int);
struct vfsmount *(*d_automount)(struct path *);
int (*d_manage)(const struct path *, bool);
struct dentry *(*d_real)(struct dentry *, const struct inode *);
} ____cacheline_aligned;
|
2.5 模型总结
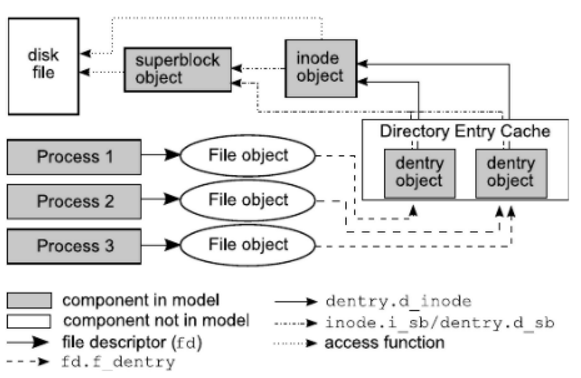
首先从内核角度看,一个已经挂载的文件系统就是由 superblock + inode 组成的。文件系统信息保存在 superblock 中,每个文件由 inode 表示。
对于一个文件的读写,就是找到对应文件的 inode,然后调用底层文件系统的 read/write 接口。一个目录 inode 对应的数据,就是其子文件或者目录的命名。
因为文件的读写增删是非常频繁的,为了在目录树中更快速的查找 inode,内核维护了 dentry 结构树,dentry 包含了文件名与 inode 的映射关系,使得不用依靠读写磁盘来查找文件对应的 inode。
从进程角度看,每个进程可以打开多文件,因此使用 file 结构代表了每个进程打开的文件,从 file -> dentry -> inode 来找到其对应的文件。
3 文件操作实现
3.1 挂载
文件系统的挂载有 mount 系统调用触发,当文件系统挂载到一个目录时,挂载点的内容就被替换为了被挂载的文件系统中的根目录的内容。前一个目录消失,无法访问,当挂载点被取消挂载后又会重新出现,并且数据不会改变。
每个挂载的文件系统都对应内核中的 mount 结构对象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
struct vfsmount {
struct dentry *mnt_root; /* root of the mounted tree */
struct super_block *mnt_sb; /* pointer to superblock */
int mnt_flags;
} __randomize_layout;
struct mount {
struct hlist_node mnt_hash;
struct mount *mnt_parent;
struct dentry *mnt_mountpoint;
struct vfsmount mnt;
union {
struct rcu_head mnt_rcu;
struct llist_node mnt_llist;
};
#ifdef CONFIG_SMP
struct mnt_pcp __percpu *mnt_pcp;
#else
int mnt_count;
int mnt_writers;
#endif
struct list_head mnt_mounts; /* list of children, anchored here */
struct list_head mnt_child; /* and going through their mnt_child */
struct list_head mnt_instance; /* mount instance on sb->s_mounts */
const char *mnt_devname; /* Name of device e.g. /dev/dsk/hda1 */
struct list_head mnt_list;
struct list_head mnt_expire; /* link in fs-specific expiry list */
struct list_head mnt_share; /* circular list of shared mounts */
struct list_head mnt_slave_list;/* list of slave mounts */
struct list_head mnt_slave; /* slave list entry */
struct mount *mnt_master; /* slave is on master->mnt_slave_list */
struct mnt_namespace *mnt_ns; /* containing namespace */
struct mountpoint *mnt_mp; /* where is it mounted */
union {
struct hlist_node mnt_mp_list; /* list mounts with the same mountpoint */
struct hlist_node mnt_umount;
};
struct list_head mnt_umounting; /* list entry for umount propagation */
#ifdef CONFIG_FSNOTIFY
struct fsnotify_mark_connector __rcu *mnt_fsnotify_marks;
__u32 mnt_fsnotify_mask;
#endif
int mnt_id; /* mount identifier */
int mnt_group_id; /* peer group identifier */
int mnt_expiry_mark; /* true if marked for expiry */
struct hlist_head mnt_pins;
struct hlist_head mnt_stuck_children;
} __randomize_layout;
|
- mnt_parent:挂载点位于父文件系统挂载;
mnt_mountpoint:挂载点,也就是父文件系统中挂载点对应的 dentry;- mnt:包含代表的文件系统的挂载属性:
- mnt_root:文件系统根目录的 dentry;
- mnt_sb:文件系统对应的 superblock;
- mnt_flags:挂载标志;
mnt_count:挂载的引用计数;- mnt_ns:所属的 mount namespace;
- mnt_devname:挂载的设备名称,例如 /dev/sda;
- 挂载子树相关数据结构 …;
mnt_id:该挂载的唯一 id;mnt_group_id:同组的挂载点的集合,即 peer group id;
3.1.1 共享子树
普通的挂载理解起来并不难,但是涉及到 bind mount 与 mount namespace 后,事情开始不一样了起来。想象几个场景:
- 如果系统新添加了磁盘,因为容器间 mount namespace 隔离了挂载信息,如果容器想用这个磁盘,是否只能手动进行挂载。
Shared subtrees 可以帮助我们解决这个问题。
共享子树 就是一种控制子挂载点能否在其他地方被看到的技术,只会在 bind mount 和 mount namespace 中被使用到。
这个概念比较绕,并且也不会常常用到,可以先跳过。
首先,需要先知道两个概念:
peer group:一个或多个挂载点的集合,同组的挂载之间会共享挂载信息,也就是可以看到。
目前有两种情况会让两个挂载点属于同一个 peer group:
- 使用 mount –bind,并且挂载的 propagation type 为 share,这样源目录和目标目录属于同一个 peer group(前提是源是一个挂载点,而不是普通文件或者普通目录)。
- 当创建新的 mount namespace 时,新 namespace 会拷贝一份老 namespace 的挂载点信息,于是新的和老的 namespace 里面的相同挂载点就会属于同一个 peer group。
propagation type:每个挂载点都有一个 type 标志,由它决定同一个 peer group 里的其他的挂载点下面是不是也会创建和移除相应的挂载点。
目前包含四种类型的 propagation type:
- MS_SHARED:挂载信息在同一个 peer group 的不同挂载点之间共享传播;
- MS_PRIVATE:挂载信息不共享,设置 private 的挂载点不属于任何的 peer group;
- MS_SLAVE:传播是单向的,同一个 peer group 中,master 的挂载点下面发生变化会共享到 slave。反之,slave 下变化不会影响 master;
- MS_UNBINDABLE:和 MS_PRIVATE 相同,只是这种类型挂载点不能作为 bind mount;
可以看到,peer cgroup 的概念就是 mount 结构中的 mnt_group_id,各个不同的 type 的子挂载,会被保存在不同的 mount 的链表中。
有个大神给出了清晰的示例与解释,见:Shared subtrees
3.2 查找 inode
查找 inode 应该是最常见的操作了,当你要打开文件或者进入目录,内核第一个任务就是要根据其路径,来查找到对应的 inode。
因为 dentry 的存在,查找自然分为了:通过 dentry 缓存查找,以及通过实际的读文件系统查找。
先看下通过 dentry 缓存查找:
- 解析文件路径,然后不断查找对应的 dentry。
例如 /a/b/c,先通过 root dentry 查找 a 对应的 dentry,接着通过 a dentry 查找 b,不断循环。
- 因为 dentry 只是缓存,所以需要使用 d_revalidate() 来检查 dentry 是否是有效地。
- 返回有效 dentry 的 inode。
当对应 dentry 不存在,或者无效之后,就会通过文件系统 inode 操作 lookup() 接口,通过底层的文件系统进行查找,并将其重新记录到 dentry 中。
参考