Linux 网络收发包过程总结
总结系列的文章是自己的学习或使用后,对相关知识的一个总结,用于后续可以快速复习与回顾。
本文是对 Linux 网络收发包一个总结,基本内容来源于网络的学习,以及自己观摩了下源码。
1 背景知识
1.1 中断
中断终止 CPU 执行流,立即执行必要的处理程序。分为两个类型:
- 同步中断和异常:由 CPU 自身产生。例如程序崩溃、缺页异常;
- 异步中断:由 IO 设备产生,任意时间可能发生;
两种中断发生后,CPU 会切换至内核态,并执行 中断处理程序。
对于异步中断,因为会停止当前执行的进程,所以内核要确保中断处理程序尽快完成,尽快返还 CPU。同样,也会阻塞 IO 设备的下一次中断,Linux 将异步中断分为了 硬件中断 与 中断下半部。
1.1.1 硬件中断
硬件中断 指硬件设备发起信号中断 CPU 执行,CPU 立即进行中断的处理。
实际上,为了不长时间阻塞与中断处理,硬中断往往启动到的是一个通知的作用。例如网卡收到数据包,并通过 DMA 写入 ringbuffer 后,会通过硬中断通知 CPU 从 ringbuffer 读取并处理数据。
通过 /proc/interrupts 可以看到硬中断的触发次数:
|
|
- 第一行:IRQ 编号;
- 第二行:每个 CPU 的中断次数;
- 第三行:中断的类型;
- 第四行:??;
- 第五行:中断发起的设备名;
平时可能只需要关注第五行设备名称就行,因为可能要过滤出网卡对应队列的中断,然后将其绑定触发的 CPU,见 网卡多队列。
1.1.2 中断下半部
中断下半部 包含三种处理方式:
-
软中断 softirq:固定的 32 个接口,只留给对时间要求最严格的下半部使用。查看
/proc/softirqs文件 可以看到目前支持的软中断:命名 含义 HI TIMER 定时中断 NET_TX 网络发送 NET_RX 网络接收 BLOCK IRQ_POLL TASKLET tasklet 软中断扩展 SCHED 内核调度 HRTIMER RCU RCU 锁 -
tasklet:因为软中断只有固定的 32 个,为了支持扩展,tasklet 基于软中断时间,在不同处理器上运行,并且支持通过代码动态注册; -
工作队列 work queue:将一个中断的部分工作推后,可以实现一些 tasklet 不能实现的工作(比如可以睡眠)。一些内核线程会不断处理工作队列的数据,其运行在进程上下文中,并且可以睡眠以及被重新调度。目前,
kworker 内核线程负责处理这个工作。
对于软中断与 tasklet,如果大量出现时,为了不一直进行 CPU 中断,内核会唤醒 ksoftirqd 内核线程进行异步的处理。每个处理器有一个 ksoftirqd/n 线程,n 为 CPU 编号。
2 网卡层
2.1 网卡多队列
网卡与系统传输数据包通过两个环形队列:TX ring buffer、RX ring buffer,也称为 DMA 环形队列。平时所说的设置网卡多队列指的就是设置这个环形队列的数量。
当网卡收到帧时,会通过哈希来决定将帧放在哪个 ring buffer 上,然后通过硬中断通知其对应的 CPU 处理。
默认下,处理环形队列数据由 CPU0 负责,可以通过配置 中断亲和性,或者通过开启 irqbalance service 将中断均衡到各个 CPU 上。
2.1.1 配置网卡队列
通过 ethool -l/-L <nic> 命令查看与配置网卡的队列数,通常配置的与机器 CPU 个数一样(如果网卡支持的话):
|
|
设置后,你在 /sys/class/net/<nic>/queues/ 可以看到对应的收发队列目录:
|
|
在 /proc/interrupts 中也可以看到各个队列对各个 CPU 的中断次数:
|
|
通过 ethtool -g/-G <nic> 可以查看与配置 ring buffer 的长度:
|
|
2.1.2 配置中断亲和性
如果你发现 CPU0 的中断很高,那么就很有可能所有网卡队列的中断都打到了 CPU0 上。可以通过 /proc/irq/<id>/smp_affinity_list 查看指定编号的中断的对应允许的 CPU。
|
|
- 62-70 的网卡队列中断都打到了不同的 CPU 上;
通过写入 echo "<bitmark>" > /proc/irq/<id>/smp_affinity 可以中断绑定的 CPU,bitmark 的每个位对应一个 CPU,例如 “0x1111” 表示 CPU 0-3 都可以处理这个中断。
当然,你也可以通过 irqbalance 来均衡各个 CPU 的中断,动态的改变中断与绑定的 CPU。不过,irqbalance 不仅仅针对网卡队列中断,还会调整其他的。
如果你的网卡不支持多队列,可以尝试配置 RPS。
2.2 接收数据
先来看第一个阶段,网卡接收到数据是如何处理的。
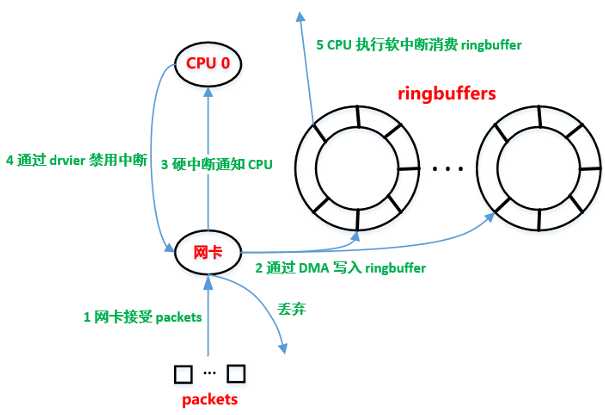
-
packet 进入物理网卡,物理网卡会根据目的 mac 判断是否丢弃(除非混杂模式);
-
网卡通过 DMA 方式将 packet 写入到 ringbuffer
ringbuffer 由网卡驱动程序分配并初始化。
-
网卡通过硬中断通知 CPU,有数据来了。
-
CPU 根据中断执行中断处理函数,该函数会调用网卡驱动函数。
-
驱动程序先禁用网卡中断(NAPI),表示网卡下次直接写到 ringbuffer 即可,不需要中断通知了。
这样避免 CPU 不断被中断。
-
驱动程序启动软中断,让 CPU 执行软中断处理函数不断从 ringbuffer 读取并处理 packet。
网卡多队列就是在这里生效,网卡会将 packet 放置到不同的 ringbuffer,不同的 ringbuffer 会中断不同的 CPU(如果设置了中断亲和性),使得各个 CPU 的队列硬中断是均衡的。
2.3 发送数据
网络设备通过驱动函数发送数据后,就归网卡驱动管了,不同的驱动有着不同的处理方式。
大致的流程如下:
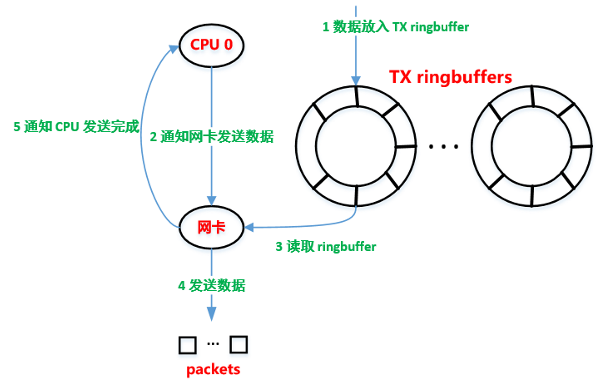
- 将 sk_buff 放入 TX ringbuff。
- 通知网卡发送数据。
- 网卡发送完数据后,通过中断通知 CPU。
- 收到中断后,进行 sk_buff 的清理工作。
当然,网卡驱动还有一些与 net_device 打交道的地方,比如网卡的队列满了,需要告诉上层不要再发了,等队列有空闲的时候,再通知上层接着发数据。
3 网络访问层
3.1 net_device
每个网络设备都表示为 net_device 一个实例。不同类型的网络设备都会有 net_device 表示,而其相关操作函数的实现不同。
net_device 是针对于 namespace 的,通过 sysfs 你可以看到当前命名空间下所有的 net_device。
|
|
net_device 包含了设备相关的所有信息,定义很长, 下面经过简化:
|
|
- name[IFNAMSIZ] :设备命名;
- irq :irq 编号;
- ifindex :设备编号;
- mtu :设备的最大传输单元;
- netdev_ops :设备的操作接口,不同类型的接口有着不同的操作实现;
- dev_addr :网卡硬件地址;
- _rx :数据包接收队列(ringbuffer);
- _tx :数据包发送队列;
- qdisc : 设备进入的 qdisc;
- ingress_queue :ingress 队列;
- 其他包含一些 XDP 相关,统计相关等字段;
大多数的统计信息都可以在对应设备的 sysfs 目录中找到。
3.2 GRO
GRO 用于将 jumbo frame(超过 1500B)的多个分片合并,然后将给上层处理,以减少上层处理数据包的数量。
通过 ethtool -k/K <nic> 查和设置 GRO。
3.3 RPS XPS RFS
3.3.1 RPS
网卡多队列需要硬件的支持,而 RPS 这些则是软件实现多队列,将包让指定的 CPU 去处理。通常情况,当网卡队列数小于 CPU 个数时,可以让 RPS 进一步利用多余的 CPU,让其去处理中断。
开启 RPS 后,数据会由经由被中断 CPU 转发,由其他 CPU 处理。流程如下:
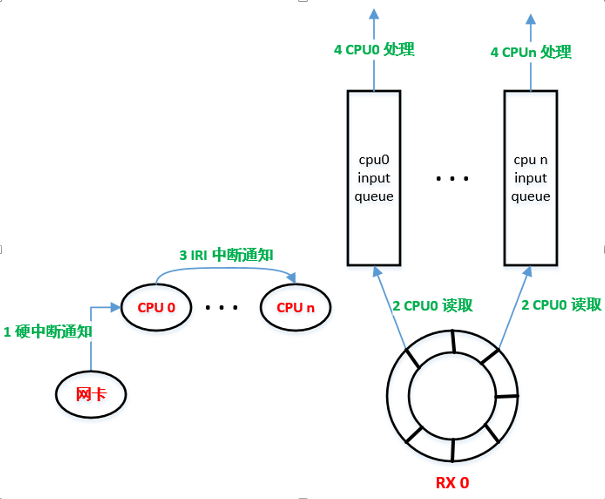
- 当网卡收到数据存入 ring buffer 后,还是通知指定 CPUx 从 ringbuffer 取出数据;
- 不过接下来,CPUx 会为每个 packet 哈希放入其他 CPU 的 input_pkt_queue 中。
- CPUx 通过 Inter-processor Interrupt (IPI) 中断告知其他 CPU,处理自己的 input_pkt_queue ;
- 其他 CPU 从各个的 input_pkt_queue 中取出数据包,并处理之后的流程;
可以看到,RPS 不是用于减少 CPU 软中断的次数,而是用于将数据包处理时间均摊到各个 CPU 上,也就是减少单个 CPU 的软中断执行时间(%soft)。
|
|
3.3.2 RFS
RFS 一般和 RPS 配合工作。
RPS 将受到的 packet 经过哈希发配到不同的 CPU input_pkt_queue。而 RFS 会根据 packet 的数据流,发送到对应被处理的 CPU input_pkt_queue 上,即同一个数据流的 packet 会被路由到处理当前数据流的 CPU 上,从而提高 CPU cache 的命中率。
RFS 默认是关闭的,需要通过配置生效,一般推荐的配置如下:
|
|
3.3.3 XPS
XPS 则是发送时的多队列处理。
3.4 接收数据
在网卡层中,最后由异步的软中断处理函数来异步的从里 ringbuffer 的数据。而这由内核线程 ksoftirqd 来调用对应的网络软中断函数处理。
所以,在数据包到达 socket buffer 前,数据处理都是由 ksoftirqd 线程执行的,也就是算在软中断处理时间里的。
-
ksoftirqd 调用驱动程序的 poll 函数来一个个处理 packet。
如果没有 packet 的话,就会重新启动网卡硬中断,等待下一次重新的流程。
-
poll 函数将读取的每个 packet,转换为 sk_buff 数据格式,并分析其传输层协议。
-
(可选)如果开启了 GRO,那么进行 GRO 的处理。
-
如果开启了 RPS,那么进行 RPS 的处理,否则放入当前 CPU 的 input_pkt_queue。
RPS 处理的流程如下:
- 当前 CPU 将 sk_buff 放到其他 CPU 的 input_pkt_queue 中。如果 input_pkt_queue 满的话,packet 会被丢弃。
- CPU 通过 IPI 硬中断通知其他 CPU 处理自己的 input_pkt_queue,也就是走 11 步流程。
到这里,而无论是否开启 RPS,接下来就是 CPU 从各自 input_pkt_queue 取出 sk_buff 并处理。
- CPU 查看 socket 是否是 AF_PACKET 类型的。如果是的话复制一份数据处理(例如 tcpdump 抓这里的包)。
- 调用对应协议栈的函数,将数据包解析出网络层协议,并交给对应的协议栈处理。
3.5 发送数据
接受到网络层的数据后,来到网络访问层会经过一个非常重要的系统:Traffic Controller。这是接收数据时不会经过。
-
根据 sk_buff 中的设备信息,获取对应 net_device.qdisc。
如果 qdisc 存在的话,走流量控制系统,可能会丢弃包:
TODO
-
拷贝一份 sk_buff 给 “packet taps”。
-
调用具体驱动的发送数据的函数发送。
4 网络层
网络访问层在接受到数据后,调用各个网络层协议的处理函数,进行 sk_buff 的处理。当然,我们下面说的是 IP 协议。
4.1 sk_buff
网卡接受到的数据包,整个在内核中传递使用的都是 sk_buff 数据结构。网络的各个层都是使用的同一个 sk_buff 对象,而无需进行数据的复制,使得性能更高。
sk_buff 包含各个指针执行对应数据的内存区域,并且表示其协议的 head data 等区域。
|
|
head,end为整个数据包的头尾内存地址;data,tail为当前层对应的数据的头尾内存地址;- transport_header,network_header,mac_header 传输层、网络层、链路层 header 的内存地址;
看图可能更好理解,sk_buff 通过指针将数据包各个区域表示出来了,而在各个协议层之间移动则是移动 data 与 tail 指针。

sk_buff_head 表示 sk_buff 组成的链表,这个结构就是 RPS 各个 CPU 的队列,以及 socket buffer 的实现。
|
|
4.2 netfilter
netfilter 是一个在内核框架,位于网络层,可以根据动态的条件过滤或操作分组。
主要包含如下功能:
- filter:根据分组元信息,对不同数据流进行分组过滤;
- NAT:根据规则来转换 source ip 或者 destination ip;
- mangle: 根据特定分组拆分与修改;
针对不同的阶段,内核代码中会存在不同的 hook 点,如下图:
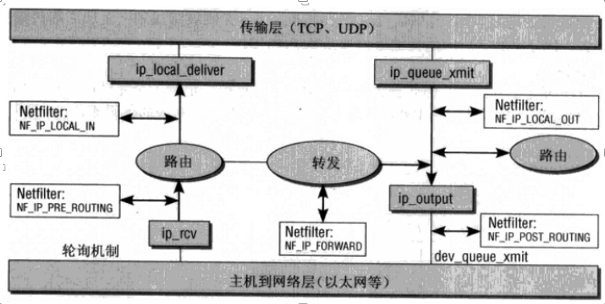
4.3 接收数据
接受数据到这里,数据包的网络层协议已经解析过了,看一下网络层处理数据报的步骤:
- 如果其数据包的 MAC 地址不是当前网卡,那么丢弃(可能由于网卡混杂模式进来的,还是无法经过协议栈处理)。
- 经过
netfilter.PREROUTING阶段回调。 - 进行路由判断:如果目的 IP 是本机 IP,那么接受该包。如果不是本机 IP,判断是否要路由。
- 经过
netfilter.LOCALIN阶段回调。 - 进入传输层。
可以看到,如果仅仅是简单的接收数据包很简单,只要经过 netfilter 的回调即可。
4.4 路由数据
当接受数据时发现数据包不是发往本机时,就会判断是否需要进行路由。
路由的前提是:机器开启了 ip forward 功能,否则会直接丢包。
|
|
看一下路由对数据包的处理:
- 检查是否开启 ip forward 功能,没有开启的话数据包会执行丢弃。
- 经过
netfilter.FORWARD阶段回调。 - 走正常的发包流程发送数据包(会经过
netfilter.POSTROUTING阶段回调)
4.5 发送数据
- 在 sk_buff 指向的数据区设置好 IP 报文头。
- 调用
netfilter.LOCALOUT阶段回调。 - 调用相关协议的发送函数(IP 协议或其他),将出口网卡设备信息写入 sk_buff。
- 调用
netfilter.POSTOUTPUT阶段回调。 - POSTOUTPUT 可能设置了 SNAT,从而导致路由信息变化,如果发生变化重新重新回到 3。
- 根据目的 IP,从路由表中获取下一跳的地址,然后在 ARP 缓存表中找到下一跳的 neigh 信息。
- 如果没有 neigh 信息,那么会进行一个 ARP 请求,尝试得到下一跳的 mac 地址。
到这里,得到了下一跳设备的 mac 地址,将其填入 sk_buff 并调用下一层的接口。
5 传输层
5.1 sock
sock 是 socket 在内核的表示结构,每个 sock 对应于一个用户态使用的 socket。TCP UDP 都是基于该结构来实现的。
其中,sock 最主要的属性就是常说的 socket buffer 了。
|
|
sk_state:TCP 的状态;sk_receive_queuesk_write_queue:接受/发送队列(buffer);- rcvbuf,sndbuf :接受/发送队列的大小,单位 B;
sk_ack_backlog:经过三次握手后,等待 accept() 的全连接队列;
5.1.1 配置 socket buffer 大小
通过 sysctl 可以配置 TCP、UDP 的接受与发送缓冲区大小:
|
|
每个设置包含三个值,min、default、max。内核会根据当前的可用内存动态调节队列的大小;
5.2 UDP 层
5.2.1 接收数据
先从简单的 UDP 处理开始看:
- 对数据包进行一致性检查。
- 根据目的 IP 与目的 port,在 udptable(包含机器所有的 udp sock)查找对应的 sock。没有找到则会丢弃数据包,否则继续。
- 检查 receive buffer 是否满,如果满了则会直接丢弃数据包。
- 检查数据包是否满足 BPF socket filter,如果不满足则直接丢弃数据包。
- 将数据包放入 receive buffer。
- 调用回调函数,以通知数据包已经准备好。这会将阻塞等待数据包到来的用户态程序唤醒。
UDP 的处理很简单,找到对应的 sock 结构,然后将其放入到队列中,唤醒用户态程序。
5.2.2 发送数据
发送操作与接收不是对称的,因为在发送时就要确定出口的设备,来确认包是否会被直接丢弃。
- 根据机器的路由表和目的 IP,决定数据包应该从哪个设备发送出去。如果根据路由表无法到达目的地址,直接丢弃包。
- 如果 socket 没有绑定源 IP,那么就使用设备的源 IP。
- 根据获取到路由信息,将 msg 构建为 sk_buff 结构体。
- 向 sk_buff 的数据区填充 UDP 包头,然后调用 IP 层相关函数。
UDP 不存在 send buffer,数据直接会发送出去,因为 UDP 没有拥塞控制。
设置 socket SO_SNDBUF 选项时,对于 UDP 这是每次发送数据的最大值,超过的话发送会直接返回 ENOBUFS。
总结
整个内核网络收发是个很复杂的模块,可能好多地方的细节都没有涉及,也有可能有理解错误的地方。
所幸内核实现层次分明的比较清楚,因此可以一层层观察其对应负责的行为。
在一个普通程序员的角度下,首先需要理解网络包收发涉及到的各个层的作用:网卡层、网络访问层、网络层、传输层。
对于各个层,需要知道一些包处理的关键点的所处于的位置,包括:网卡多队列、流量控制、netfilter、r/w buffer 等;
目前整理的主要的点如下:
- 网卡层
- 网络访问层
- 网络访问层接受数据;
- 网络访问层发送数据;
- ksoftiqrd 线程的任务;
- RPS、XPS、RFS 的概念;
- TC 流量控制处理的位置;
- XDP 处理的位置;
- 网络层
- 传输层
- sock 结构的概念;
- UDP 的 recv socket buffer;
- TCP 的半连接队列,全连接队列,r/w socket buffer;