总结系列的文章是自己的学习或使用后,对相关知识的一个总结,用于后续可以快速复习与回顾。
本文主要总结一些遇到的虚拟机使用存储与网络的方式,挖了许多坑,不断补充中。
下面所有的虚拟机启动都使用 libvirt,通过修改其配置文件来设置网络或者存储,省略了虚拟机的启动、停止等操作命令。
1 virtio 概述
KVM 在 IO 虚拟化方面,传统的方式是使用 QEMU 纯软件方式模拟网卡、磁盘。
KVM 中,可以在客户机使用 半虚拟化驱动 来提高客户机性能。
目前,采用的是 virtio 这个设备驱动标准框架。
1.1 全模拟 I/O 设备基本原理
纯软件模拟 I/O 如下图所示:
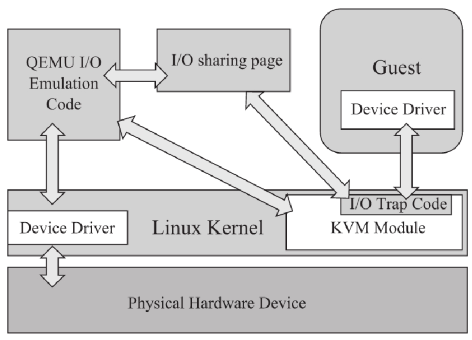
- 客户机中设备驱动程序(Device Driver)发起 I/O 操作请求时,KVM 内核模块会拦截这次请求,然后将请求信息放到 I/O 共享页(sharing page);
- KVM 模块通知用户空间 QEMU 程序(客户机对应 qemu 进程的一个线程)有 I/O 请求;
- QEMU 模拟程序根据 I/O 请求信息,交由硬件模拟代码(Emulation Code)模拟 I/O 请求,阻塞等待 I/O 结果;
- 如果是普通的 I/O 请求完成后,将结果放回到 I/O 共享页;
如果客户机是通过 DMA 访问大块 I/O 时,QEMU 模拟程序会直接通过内存映射的将结果直接写到客户机内存中,并通知 KVM 模块客户机 DMA 操作已经完成;
- KVM 内核模块读取 I/O 共享页中结果,将结果返回给客户机;
或者,接受到 QEMU 通知,通知客户机 DMA 操作已经完成;
QEMU 模拟 I/O 设备的优点:可以通过软件模拟出各种设备,兼容性好。但是也有明显缺点:每次 I/O 操作比较长,有较多的 VMEntry、VMExit 发生,需要多次上下文切换与数据复制,性能很差。
1.2 virtio 基本原理
virtio 是一个在 Hypervisor 上抽象 API 接口,让客户机知道运行与虚拟化环境中,进而根据 virtio 标准与 Hypervisor 协作,从而在客户机达到更好性能。
其 virtio 基本结构如下:
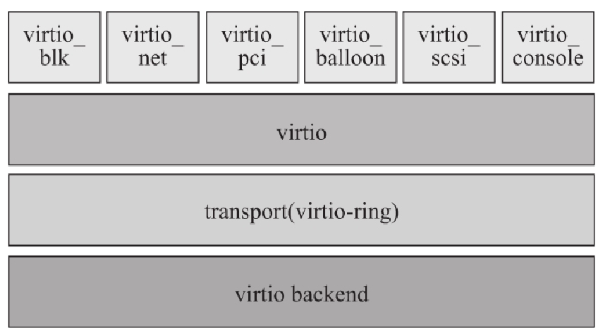
- 前端驱动 是在客户机中的驱动模块,如 virtio-blk、virtio-net 等;
- 后端处理程序 在 QEMU 中实现,执行具体的 I/O 操作;
virtio 是虚拟队列接口,在逻辑上将前端驱动附加到后端处理程序,虚拟队列实际上被实现为跨越客户机操作系统和 Hypervisor 的衔接点,该衔接点可以用任意方式实现,前提是前后端都遵循标准实现。
一个前端驱动可以有 0 或多个队列,例如 virtio-net 使用两个虚拟队列(接受+发送)。virtio-ring 实现了环形缓冲区(ring buffer),用于保存前端驱动和后端处理程序执行的信息。
环形缓冲区可以一次性保存前端驱动多个 I/O 请求,并交由后端驱动批量处理,最后实际调用宿主机设备驱动实现的设备 I/O 操作,以提升效率。
virtio 的性能很好,一般都推荐使用 virtio。但是,virtio 要求客户机必须安装特定的 virtio 驱动,并且按照 virtio 规定格式传输数据,一些老的 Linux 系统可能不支持。
在客户机中查看是否存在 virtio 相关内核模块,以确定系统是否支持 virtio:
1
2
3
4
5
|
[root@kvm-guest ~]# lsmod | grep virtio
virtio_net 28024 0
virtio_pci 22913 0
virtio_ring 21524 2 virtio_net,virtio_pci
virtio 15008 2 virtio_net,virtio_pci
|
其中,virtio、virtio_ring、virtio_pci 等驱动提供对 virtio API 支持,任何 virtio 前端驱动都必须使用。
1.3 vhost
正如 前面所述,virtio 分为前后端,而后端默认为用户空间的 QEMU 进程。由 QEMU 进程模拟虚拟机的命令,在将结果返回给虚拟机。可以看到,这里存在着一次 用户空间至内核空间的转换。
而 vhost 出现就是用于优化这一次的转换。vhost 是宿主机中的一个内核模块,用于和虚拟机直接进行通信,也是通过 virtio 提供的数据队列进行通信。
目前,网络支持有 vhost-net,块设备支持有 vhost-blk,它们都依赖于基础的内核模块 vhost。
1
2
3
4
|
$ lsmod | grep vhost
vhost_net 28672 1
vhost 53248 1 vhost_net
vhost_iotlb 16384 1 vhost
|
1.4 总结
首先,需要明白 virtio 为什么比纯模拟的方式快?
最主要因为纯模拟的方式存在多次内核 KVM 与用户空间 QEMU 进程的数据交互,简单点说,客户机需要 KVM 进行数据的中转。
而 virtio 消除了 KVM 进行数据的中转,通过一套标准框架实现虚拟机与 QEMU 进程的直接信息交互。也是因此,虚拟机需要使用特殊的 virtio 相关的驱动,也就知道了自己处于虚拟化环境,所以是半虚拟化。
其次,需要明确,virtio 由前后端组成,其中后端是由 QEMU 实现的,目前主流的 QEMU 版本都实现了,不需要 care。而需要注意的是,virtio 的前端是要在虚拟机中满足,也就是相关的 virtio 驱动,这在使用时需要进行确认。
而 virtio 的通信方式中,还存在 QEMU 模拟命令执行这一个优化点,因此,vhost 出现优化了这一次的用户空间至内核空间的切换。
2 设备直接分配
2.1 PCI 设备直接分配
PCI 设备直接分配 允许将宿主机的物理 PCI(或 PCI-E)设备直接分配给客户机完全使用。
设备直接分配相当于虚拟机直接使用硬件设备,也就没有了 QEMU 进程的模拟,因此速度最快。
但是,设备直接分配有一些条件:
- 硬件平台需要支持 Intel 硬件支持设备直接分配规范为 “Intel(R)Virtualization Technology for Directed I/O”(VT-d)或者 AMD 的规范为 “AMD-Vi”(也叫作 IOMMU)。
目前市面上的 x86 硬件平台基本都支持 VT-d,在 BIOS 中设置打开 VT-d 特性。
- 内核配置支持相关 VT-d 的特性,并且加载内核模块 vfio-pci(内核 >= 3.10)。
- 内核启动参数需要打开 intel_iommu=on(intel 平台)
1
2
3
4
5
6
7
|
$ modprobe vfio_pci
$ lsmod | grep vfio
vfio_pci 53248 0
vfio_virqfd 16384 1 vfio_pci
vfio_iommu_type1 32768 0
vfio 36864 2 vfio_iommu_type1,vfio_pci
irqbypass 16384 8 vfio_pci,kvm
|
2.2 SR-IOV
VT-d 技术只能讲一个物理设备分配给一个客户机使用,为了让多个虚拟机共享同一个物理设备,PCI_SIG 组织发布了
SR-IOV 规范,该规范定义了标准化机制,用以原生的支持多个共享的设备(不一定网卡)。
目前,SR-IOV 最广泛应用在以太网设备的虚拟化方面。
SR-IOV 引入了两个新的 function:
- PF 物理功能 :PF 是一个普通的 PCI-e 设备(带有 SR-IOV 功能),在宿主机中配置和管理其他 VF,本身也可以作为独立 function 使用;
- VF 虚拟功能 :由 PF 衍生的 “轻量级” PCI-e 功能,可以分配到客户机中作为独立 function 使用;
SR-IOV 为客户机中使用的 VF 提供了独立的内存空间、中断、DMA 流,从而不需要 Hypervisor 介入数据传输。
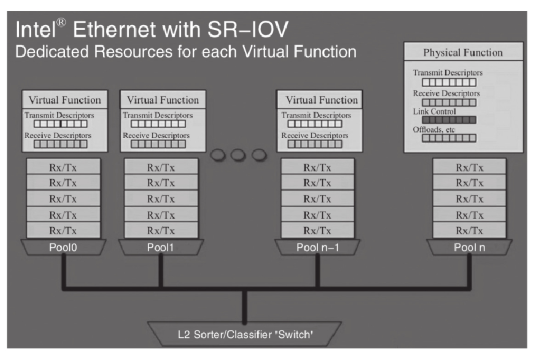
一个具有 SR-IOV 功能的设备能够被配置为 PCI 配置空间中呈现出多个 Function(1 个 PF + 多个 VF),每个 VF 有独立的配置空间和完整的 BAR(Base Address Register,基址寄存器)。
Hypervisor 通过将 VF 实际的配置空间映射到客户机看到的配置空间的方式,将一个或多个 VF 分配给一个客户机。并且,通过 Intel VT-x 和 VT-d 等硬件辅助虚拟化技术提供的内存转换技术,允许直接的 DMA 传输去往或来自一个客户机,因此几乎不需要 Hypervisor 的参与。
在客户机中看到的 VF,表现给客户机操作系统的就是一个完整的普通的设备。
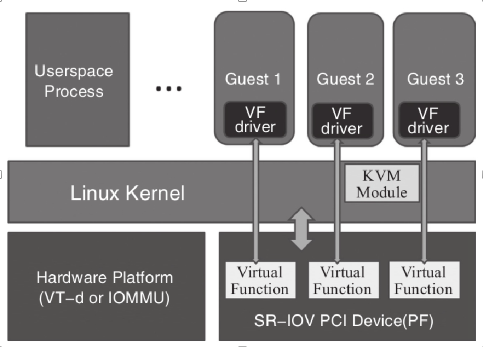
SR-IOV 需要硬件平台支持 Intel VT-x 和 VT-d(或 AMD 的 SVM 和 IOMMU)虚拟化特性,并且需要具体设备支持 SR-IOV 规范。
在 Linux 中,可以查看 PCI 信息的“Capabilities”项目,以确定设备是否具备 SR-IOV 功能:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
$ lspci -s 82:00.0 -v
82:00.0 Ethernet controller: Intel Corporation I350 Gigabit Network Connection (rev 01)
Flags: bus master, fast devsel, latency 0, IRQ 38, NUMA node 1
Memory at d0100000 (32-bit, non-prefetchable) [size=1M]
I/O ports at c020 [size=32]
Memory at d0204000 (32-bit, non-prefetchable) [size=16K]
Expansion ROM at d0400000 [disabled] [size=1M]
Capabilities: [40] Power Management version 3
Capabilities: [50] MSI: Enable- Count=1/1 Maskable+ 64bit+
Capabilities: [70] MSI-X: Enable+ Count=10 Masked-
Capabilities: [a0] Express Endpoint, MSI 00
Capabilities: [100] Advanced Error Reporting
Capabilities: [140] Device Serial Number a4-dc-be-ff-ff-17-8d-52
Capabilities: [150] Alternative Routing-ID Interpretation (ARI)
Capabilities: [160] Single Root I/O Virtualization (SR-IOV)
Capabilities: [1a0] Transaction Processing Hints
Capabilities: [1c0] Latency Tolerance Reporting
Capabilities: [1d0] Access Control Services
Kernel driver in use: igb
Kernel modules: igb
|
- “Capabilities: [160] Single Root I/O Virtualization (SR-IOV)" 表示网卡支持 SR-IOV 功能
具体使用方式见网络模式中的示例。
3 存储模式
下面的磁盘测试都是以 4k 随机读写测试,命令如下:
1
2
3
|
fio -thread -name=${DISK} -filename=${DISK} \
-ioengine=libaio -direct=1 -bs=4k -rw=randrw -iodepth=32 \
-size=8G -rw=readrw
|
说明,测试仅仅适用于简单对比各个模式之间性能差异,而不是标准的基准测试,不能作为靠谱数据。
3.1 纯模拟
纯模拟是最简单的方式,所有的 IO 请求发送给 QEMU,由 QEMU 在宿主机执行后将结果返回给虚拟机中(见 1.1)。
创建一个 qcow2 文件,并将其以 sata 驱动方式提供给虚拟机:
1
2
3
4
5
6
7
8
|
…
<disk type='file' device='disk'>
<driver name='qemu' type='qcow2'/>
<source file='/root/disk1.qcow2'/>
<target dev='sda' bus='sata'/>
<address type='drive' controller='0' bus='0' target='0' unit='0'/>
</disk>
…
|
在虚拟机中,可以看到对应的磁盘与对应的驱动:
1
2
3
4
5
6
7
8
|
[root@localhost ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 500G 0 disk
vda 253:0 0 500G 0 disk
└─vda1 253:1 0 500G 0 part /
[root@localhost ~]# lspci
…
00:09.0 SATA controller: Intel Corporation 82801IR/IO/IH (ICH9R/DO/DH) 6 port SATA Controller [AHCI mode] (rev 02)
|
压测结果:
- read: IOPS=9183, BW=35.9MiB/s (37.6MB/s)(4098MiB/114246msec)
- write: IOPS=9172, BW=35.8MiB/s (37.6MB/s)(4094MiB/114246msec)
3.2 virtio-blk
virtio-blk 实现了 virtio 标准,在虚拟机中使用 virtio 驱动,加速存储的访问。当然,需要客户机中系统支持 virtio-blk 内核模块。
1
2
|
[root@localhost ~]# lsmod | grep blk
virtio_blk 18323 2
|
目前,virtio-blk 可用于宿主机文件、裸设备、LVM 设备,挂载到虚拟机后命名为 vdx。
将 <disk>.<target> 中的 bus 改为 virtio,就是使用 virtio-blk 方式。
1
2
3
4
5
6
7
8
|
…
<disk type='file' device='disk'>
<driver name='qemu' type='qcow2'/>
<source file='/root/disk1.qcow2'/>
<target dev='sda' bus='virtio'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x0a' function='0x0'/>
</disk>
…
|
不过使用 virtio 驱动,设置的 dev 名称会失效,自动使用 vdx 这种命名方式。在虚拟机中看到对应的磁盘以及驱动:
1
2
3
4
5
6
7
8
|
[root@localhost ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
vda 253:0 0 500G 0 disk
└─vda1 253:1 0 500G 0 part /
vdb 253:16 0 500G 0 disk
[root@localhost ~]# lspci
…
00:0a.0 SCSI storage controller: Red Hat, Inc. Virtio block device
|
压测结果,可以看到,比纯模拟要快很多:
- read: IOPS=41.7k, BW=163MiB/s (171MB/s)(4098MiB/25145msec)
- write: IOPS=41.7k, BW=163MiB/s (171MB/s)(4094MiB/25145msec)
virtio-blk 虽然提供了很高的存储访问性能,但是其设计上也有着一些缺点:
- virtio blk 的范围有限,这使得新的命令实现变得复杂。每次开发一个新命令时,virtio blk 驱动程序都必须在每个客户机中更新
- virtio blk 将 PCI 功能和存储设备映射为 1:1,一个映射就需要占用虚拟机一个 PCI 地址,限制了可扩展性。
- virtio blk 不是真正的 SCSI 设备。这会导致一些应用程序在从物理机移动到虚拟机时中断。
3.3 virtio-scsi
virito-scsi 有着与 virtio-blk 相同的性能,但是改善了 virtio-blk 的相关缺点,其中最大的优势就是 virtio-scsi 可以允许虚拟机处理数百个设备,而 virtio-blk 只能处理大约 30 个设备就会耗尽 PCI 插槽。
因为 virtio-scsi 在虚拟机里使用的是 scsi 驱动,因此设备的命名也变为了 sdx。
将磁盘的驱动设置为 scsi,同时将 scsi 驱动设置为使用 virtio-scsi(默认使用的驱动是 lsi):
1
2
3
4
5
6
7
8
9
|
…
<disk type='file' device='disk'>
<driver name='qemu' type='qcow2'/>
<source file='/root/disk1.qcow2'/>
<target dev='sdc' bus='scsi'/>
<address type='drive' controller='0' bus='0' target='0' unit='2'/>
</disk>
<controller type='scsi' index='0' model='virtio-scsi'/>
…
|
- 可以看到,<address> 中设置相关设备地址时,可以看到不是设置 pci 槽地址,而是设置设备对应 SCSI 映射地址,因此通过增加 “target” 属性就可以添加多个硬盘,不需要占用多个 PCI 槽;
虚拟机中看到对应的块设备 “sda”,以及驱动 “Virtio SCSI”:
1
2
3
4
5
6
7
8
|
[root@localhost ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 500G 0 disk
vda 253:0 0 500G 0 disk
└─vda1 253:1 0 500G 0 part /
[root@localhost ~]# lspci
…
00:08.0 SCSI storage controller: Red Hat, Inc. Virtio SCSI
|
压测结果:
- read: IOPS=45.5k, BW=178MiB/s (186MB/s)(4098MiB/23055msec)
- write: IOPS=46.2k, BW=180MiB/s (189MB/s)(4094MiB/22695msec)
目前,virtio-scsi 还存在一种设备直通的模式,IO 性能更高(具体实现原理还不了解)。但是,这种模式还能用于块设备,并且是使用 scsi 协议的块设备(测试文件、usb 都不支持)。
通过设置 device=“lun” 使用:
1
2
3
4
5
6
7
8
9
|
...
<disk type='block' device='lun'>
<driver name='qemu' type='raw'/>
<source dev='/dev/sda'/>
<target dev='sdc' bus='scsi'/>
<address type='drive' controller='0' bus='0' target='0' unit='2'/>
</disk>
<controller type='scsi' index='0' model='virtio-scsi' />
...
|
- 使用 lun 方式,并指定使用宿主机块设备 sda
虚拟机中看到对应块设备 “sda”,以及驱动 "” :
1
2
3
4
5
6
7
8
|
[root@localhost ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 465.8G 0 disk
vda 253:0 0 500G 0 disk
└─vda1 253:1 0 500G 0 part /
[root@localhost ~]# lspci
…
00:08.0 SCSI storage controller: Red Hat, Inc. Virtio SCSI
|
发现的问题
在使用 lun 分配磁盘时,发现虚拟机内部对磁盘的修改,在宿主机上是无法可见的(可能出现磁盘文件系统 UUID 都不一致的问题)。并且,在虚拟机内部给磁盘创建文件系统还会出现有报错的情况。
如果是要将 scsi 磁盘单独分给虚拟机,推荐使用设备直接分配中的 scsi 设备分配。
3.4 设备直接分配
3.4.1 PCI 设备
在 2.1 PCI 设备直接分配 中所说,PCI 设备都支持进行设备直接分配,使得虚拟机中直接对 PCI 设备进行访问,速度最快。nvme 磁盘可以使用这种方式。
使用设备直接分配时,需要现在宿主机上取消对应设备的驱动绑定,然后将其分配给虚拟机,然后 libvirt 中配置好相关参数后,会自动帮我们执行这些步骤。
在设备 xml 配置文件中添加 <hostdev> 项,指定对应的设备 PCI 地址,来直接分配设备(也可以使用 <interface type=‘hostdev’/>,这是一种 libvirt 提供的较新的配置方式,但是不兼容所有设备)。
1
2
3
4
5
6
7
|
…
<hostdev mode='subsystem' type='pci' managed='yes'>
<source>
<address domain='0x0000' bus='0x08' slot='0x00' function='0x0'/>
</source>
</hostdev>
…
|
3.4.2 SCSI 设备
对于 SCSI 磁盘,通过 PCI 无法单独分配某个磁盘,而 libvirt 中提供了 type=‘scsi’ 类型的直接分配。但是与 PCI 不同的是,scsi 无法设置 ‘managed’ 参数,也就是说宿主机上还是能够看见该 scsi 设备,如果想不可见,需要自己 unbind。
添加 scsi 类型的 <hostdev> 项,其中 <source>.<address> 中指定宿主机对应磁盘的 scsi 地址。
1
2
3
4
5
6
7
8
9
10
|
...
<hostdev mode='subsystem' type='scsi' managed='no' sgio='filtered' rawio='yes'>
<source>
<adapter name='scsi_host0'/>
<address bus='2' target='1' unit='0'/>
</source>
<address type='drive' controller='0' bus='0' target='0' unit='2'/>
</hostdev>
<controller type='scsi' index='0' model='virtio-scsi'/>
...
|
Note
这种模式还是会使用 virtio-scsi 驱动,我不确定这是否属于设备直接分配,但是在文档中其属于 passthrough 的一类
3.5 libvirt 提供的存储模型
TODO
4 网络模式
虚拟机网络的构建一般都是需要构建 宿主机网络环境 + 虚拟机虚拟网络设备,得益于 libvirt,一些常用的网络的构建只需要配置好相关配置就行,libvirt 会进行网络的构建。在 libvirt 中,一个可用的网络就称为 netowrk
首先需要明确的,下面所说的网络模式不同的在于如何让宿主机接收的数据包,到达 qemu 进程 或者 vhost 内核模块。而 qemu 进程与 vhost 模块如何将数据包传递到虚拟机中,这是虚拟化方式的问题,即全虚拟化或者半虚拟化。
更简单点说,虚拟机的网络收发有三个点:宿主机 <-> qemu/vhost <-> 虚拟机。而不同网络模式不同点在 宿主机至 qemu/vhost 阶段,而数据包到虚拟机,这就是不同虚拟化的工作了。
在下面的配置中,你会发现网络模式还需要配置 driver 选项,这就是配置具体的虚拟化方式了。但是这不是这里的重点,所以不会有特殊的说明。
libvirt 支持的网络模式有很多,下面仅仅提到我使用过的。
4.1 虚拟机网络
4.1.1 NAT Mode
NAT 网络是最简单的网络,不需要任何的依赖。通过虚拟的 bridge 网卡创建一个属于虚拟机的内网,然后在宿主机上通过 iptables 实现内网地址的 NAT。(没错,这和 docker bridge network 的原理一样)
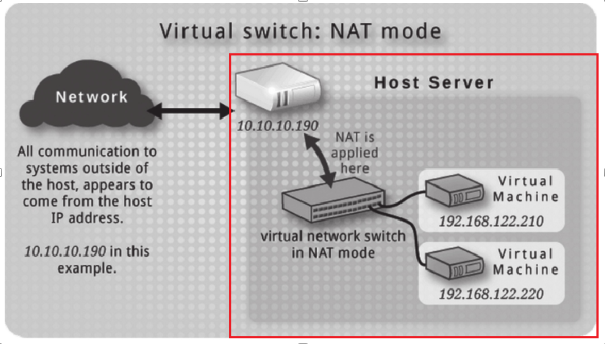
libvirt 会存在一个名为 default 的 network,其就是一个 NAT 网络。通过 virsh net-list 查看:
1
2
3
4
|
$ virsh net-list
Name State Autostart Persistent
--------------------------------------------
default active yes yes
|
其默认会被 active,也就是说宿主机环境在 libvirtd 启动后就会构建好,你可以看到对应的 bridge 网卡。
1
2
3
4
5
6
7
|
$ ip a
...
3: virbr0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default qlen 1000
link/ether 52:54:00:12:34:56 brd ff:ff:ff:ff:ff:ff
inet 172.27.0.1/16 brd 172.27.255.255 scope global galaxybr0
valid_lft forever preferred_lft forever
...
|
默认下,default 网络的内网为 192.168.122.1/24,我通过修改其配置文件 /etc/libvirt/qemu/networks/default.xml 修改了内网范围:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
$ cat /etc/libvirt/qemu/networks/default.xml
<network>
<name>default</name>
<uuid>341adece-b07a-4eb0-92f2-d92f59ed266f</uuid>
<forward mode='nat'/>
<bridge name='virbr0' stp='on' delay='0'/>
<mac address='52:54:00:12:34:56'/>
<ip address='172.27.0.1' netmask='255.255.0.0'>
<dhcp>
<range start='172.27.0.2' end='172.27.255.254'/>
</dhcp>
</ip>
</network>
|
libvirtd 会为启动的 nat 网络启动一个 dnsmasq 进程,用于提供 DNS 与 DHCP 功能,其对应配置就是对应网络的配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
$ ps x | grep dns
2185 ? S 0:00 /usr/sbin/dnsmasq --conf-file=/var/lib/libvirt/dnsmasq/default.conf --leasefile-ro --dhcp-script=/usr/libexec/libvirt_leaseshelper
$ cat /var/lib/libvirt/dnsmasq/default.conf
strict-order
pid-file=/var/run/libvirt/network/default.pid
except-interface=lo
bind-dynamic
interface=virbr0
dhcp-range=172.27.0.2,172.27.255.254,255.255.0.0
dhcp-no-override
dhcp-authoritative
dhcp-lease-max=65533
dhcp-hostsfile=/var/lib/libvirt/dnsmasq/default.hostsfile
addn-hosts=/var/lib/libvirt/dnsmasq/default.addnhosts
|
Note
这里与 docker bridge network 不同点,因为 docker 中仅仅是 namespace 隔离,容器内网卡 IP 还是可以由 docker 进入 namespace 分配,所以是 docker 承担了 dhcp 服务器的职责。
但是虚拟机和宿主机是强隔离的,因此需要虚拟机启动后去作为 dhcpclient 申请地址,因此需要一个 dhcp 服务,这就是 dnsmasq 的作用。
在 xml 配置文件中设置
<interface type=‘network’> 项,并设置
<source network=‘default’/> 使用 default network。
1
2
3
4
5
6
7
8
9
|
<inferface type='network'>
<mac address='50:54:00:87:bc:c3'/>
<source network='default'/>
<model type='virtio'/>
<driver name='vhost' txmode='iothread' ioeventfd='on' event_idx='off' queues='16'>
<host csum='off' gso='off' tso4='off' tso6='off' ecn='off' ufo='off' mrg_rxbuf='off'/>
<guest csum='off' tso4='off' tso6='off' ecn='off' ufo='off'/>
</driver>
</interface>
|
启动虚拟机后,可以看到虚拟机内部存在对应的网卡,通过 dhclient -v eth0 命令申请一个 IP,广播的 dhcp request 会被宿主机 dnsmasp 进程响应,并返回 dhcp offer。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
[root@localhost ~]# ip a
...
2: eth0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 50:54:00:87:bc:c3 brd ff:ff:ff:ff:ff:ff
[root@localhost ~]# dhclient -v eth0
...
Listening on LPF/eth0/50:54:00:87:bc:c3
Sending on LPF/eth0/50:54:00:87:bc:c3
Sending on Socket/fallback
DHCPDISCOVER on eth0 to 255.255.255.255 port 67 interval 4 (xid=0x57740476)
DHCPREQUEST on eth0 to 255.255.255.255 port 67 (xid=0x57740476)
DHCPOFFER from 172.27.0.1
DHCPACK from 172.27.0.1 (xid=0x57740476)
bound to 172.27.163.138 -- renewal in 1653 seconds.
[root@localhost ~]# ping www.baidu.com
PING www.a.shifen.com (14.215.177.38) 56(84) bytes of data.
64 bytes from 14.215.177.38 (14.215.177.38): icmp_seq=1 ttl=48 time=7.93 ms
...
|
4.1.2 Routed Mode
TODO
4.2 共享物理设备网络
4.2.1 Bridge
TODO
4.2.2 Macvtap
在 docker 的网络中,存在着 macvlan 网络,其在宿主机的物理网卡上创建 macvlan 设备,使得在二层上构建多个接口,从而让多个容器处于与宿主机同一个局域网内。在虚拟机网络中,单单 macvlan 网卡无法连接虚拟机设备与宿主机网卡,还需要一个 tap 设备连接,将 macvlan + tap 组合就是 macvtap 设备。
与 macvlan 设备相同,macvtap 同样存在:private、vepa、bridge、passthru 四种模式,下面的示例中都以 bridge 模式为例。
在 libvirt 中,当 interface type 为 direct 时,表明设备是直接附加到物理网卡上,而就会使用 macvtap 构建网络。通过 <source dev=xx mode=xx> 指定附加的物理网卡,以及 macvtap 的模式。
1
2
3
4
5
6
7
8
9
10
11
12
|
...
<interface type='direct'>
<mac address='50:54:00:87:bc:c3'/>
<source dev='eth3' mode='bridge'/>
<model type='virtio'/>
<driver name='vhost' txmode='iothread' ioeventfd='on' event_idx='off' queues='16'>
<host csum='off' gso='off' tso4='off' tso6='off' ecn='off' ufo='off' mrg_rxbuf='off'/>
<guest csum='off' tso4='off' tso6='off' ecn='off' ufo='off'/>
</driver>
<address type='pci' domain='0x0000' bus='0x00' slot='0x03' function='0x0'/>
</interface>
...
|
启动虚拟机后,在宿主机上可以看到对应的 macvtap 设备被创建,其 mac 地址也与配置中的一致。
1
2
3
4
5
6
7
8
|
$ ip a
...
5: eth3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether a4:dc:be:0a:7d:37 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.107/24 brd 192.168.1.255 scope global eth3
valid_lft forever preferred_lft forever
10: macvtap0@eth3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 500
link/ether 50:54:00:87:bc:c3 brd ff:ff:ff:ff:ff:ff
|
在虚拟机内部,可以看到对应的虚拟网卡,通过 dhcp 上层路由器获取 IP,可以发现,其网关就是宿主机的网关,其网段与宿主机一致。因此,使用 macvtap 相当于让虚拟机与宿主机处于同一个二层。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
[root@localhost ~]# dhclient -v eth0
...
Listening on LPF/eth0/50:54:00:87:bc:c3
Sending on LPF/eth0/50:54:00:87:bc:c3
Sending on Socket/fallback
DHCPREQUEST on eth0 to 255.255.255.255 port 67 (xid=0x4e586341)
DHCPNAK from 192.168.1.1 (xid=0x4e586341)
DHCPDISCOVER on eth0 to 255.255.255.255 port 67 interval 8 (xid=0x1d605c78)
DHCPREQUEST on eth0 to 255.255.255.255 port 67 (xid=0x1d605c78)
DHCPOFFER from 192.168.1.1
DHCPACK from 192.168.1.1 (xid=0x1d605c78)
bound to 192.168.1.105 -- renewal in 3423 seconds.
[root@localhost ~]# ip a
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 52:54:00:87:bc:c1 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.105/24 brd 192.168.1.255 scope global dynamic eth0
valid_lft 7023sec preferred_lft 7023sec
|
4.3 设备直接分配
前面的各种网络模式,最后还是靠着全虚拟化或者半虚拟化将数据包传递给虚拟机,而如果你有着多个可用的网卡,那么可以考虑使用设备直接分配,这是性能最高的方式。
4.3.1 PCI 网卡
在设备 xml 配置文件中添加 <hostdev> 项,指定对应的设备 PCI 地址,来直接分配设备(也可以使用 <interface type=‘hostdev’/>,这是一种 libvirt 提供的较新的配置方式,但是不兼容所有设备)。
1
2
3
4
5
6
7
|
…
<hostdev mode='subsystem' type='pci' managed='yes'>
<source>
<address domain='0x0000' bus='0x01' slot='0x00' function='0x0'/>
</source>
</hostdev>
…
|
启动虚拟机后,在宿主机上就无法看到对应的网卡了,因为对应的驱动被 libvirt 解绑了。
关闭虚拟机后,libvirt 又会重新将网卡绑定驱动,在宿主机上有可见了。
4.3.1 SR-IOV
TODO
参考