Prometheus 查询语言 PromQL
1 数据类型
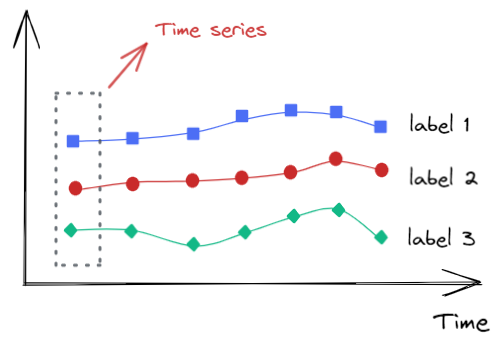
上图简单代表了时序数据库的存储。每次 Prometheus 拉取数据时,拉取到就是图中纵向的一条线,也就是一个统计数据多维度的瞬时值,也被称为 时间序列。
PromQL 将表达式归为以下四种类型:
-
即时向量 - 同一时刻的一组时间序列。可以理解为就是瞬时的样本的集合。
-
区间向量 - 一定时间范围内的一组时间序列。可以理解为有了时间范围即时向量。
-
标量 - 纯量数据,仅仅是一个数字,没有时间戳。
-
字符串 - 单引号、双引号或者反引号指定的纯字符串值。
2 Selector
2.1 Instant Vector Selector
Instant Vector Selector 查询某一时间(默认最新时间)的时间序列,并通过 label 对其进行样本筛选,得到一个即时向量。
通过 {} 中添加 label 匹配运算,来进行样本的筛选。多个匹配之间通过 , 号分隔。
| 运算符 | 匹配运算符 | 示例 |
|---|---|---|
| = | 相等匹配 | job=“mysqld_node” |
| != | 不相等匹配 | job!=“redis_expoter” |
| =~ | 正则匹配 | job=~“node_.*” |
| !~ | 正则不匹配 | job!~“nginx-.*” |
例如,我们要查找 /mnt 目录下除了 /mnt/local_pv 下的所有挂载点的大小:
|
|

Metric Name 在 Prometheus 底层会使用 label “name” 记录,因此通过 {name=“xxx”} 可以筛选 Metric 项。
不过该操作会遍历所有的 Metric 来过滤,所以要注意性能。
默认会查询最新时间的时间序列,可以通过 offset 来进行基准时间偏移。如下示例查询当前时间前一天的样本:
|
|
2.2 Range Vector Selectors
Range Vector Selectors 查询一段时间范围内的时间序列,并通过 label 匹配进行样本过滤,最后得到一个区间向量。
2.3.1 Duration
在末尾加上 [<duration>] 的方式来指定获取过去 duration 时间的样本。时间单位支持:s(秒) m(分) h(小时) d(天) w(周) y(年)。
例如,下面在前面基础上查询过去 1m 的样本:
|
|

2.3.2 Offset
使用用 offset 来指定基准时间。offset 修饰符只能跟随在 Selector 之后。
例如下面表明以 1d 前的当前时间为基准,查询过去 1m 的样本:
|
|
2.3.3 @
@ 修饰符用于指定查询中的特定时间。@ 修饰符后跟随的是一个 Unix 时间戳。
例如查询 http_requests_total 在 2021-01-04T07:40:00+00:00 的值:
|
|
同样,@ 也适用于范围查询:
|
|
3 聚合操作
Prometheus 提供了许多内置的聚合操作,聚合操作仅仅适用于一个即时向量。通过聚合操作,会得到一个新的即时向量。
聚合操作的语法如下:
|
|
aggr-op- 聚合操作名称param- 传递给操作的参数vector- 即时向量without/by- 操作即时向量前,通过 label 匹配对样本进一步进行过滤/筛选- without 按匹配到的之外的 label 分组,输出保留 label
- by 按匹配到的 label 分组,输出保留 label
例如,下面使用 without 得到节点所有 CPU 样本的平均值:
|
|
- without 去除了即时向量中所有样本的 “cpu” label,而按照剩下的 label 进行分组,相同的 label 样本进行聚合求平均值。
同样,使用 by 将所有节点所有 CPU 的按照 mode 分组,求平均:
|
|
- by 将即时向量所有样本的其他 label 去除,仅仅保留 label “mode”,然后按照 “mode” 分组聚合样本,并求平均值。
3.1 聚合操作符
下面列出了 Prometheus 提供的聚合操作符:
| 名称 | 描述 |
|---|---|
| sum(<vector>) | 将即时向量所有样本值相加 |
| max(<vector>) | 得到即时向量所有样本的最大值 |
| min(<vector>) | 得到即时向量所有样本的最小值 |
| avg(<vector>) | 得到即时向量所有样本的平均值 |
| stddev(<vector>) | 标准差,对一组数字分布情况的统计度量,用于检查异常值 |
| stdvar(<vector>) | 标准方差,标准差的平方 |
| count(<vector>) | 计数,计算样本的数量 |
| count_values(“label”, <vector>) | 对相同的 value 进行计数,统计每一个样本值出现的次数。 count_values 为根据 value 添加由参数指定的 label |
| bottomk(N, <vector>) | 对样本值进行小到大排序,返回前 N 个样本(其实不是聚合操作,因此 without 与 by 仅仅用于排序分组) |
| topk(N, <vector>) | 对样本值进行大到小排序,返回前 N 个样本(其实不是聚合操作,因此 without 与 by 仅仅用于排序分组) |
| quantile(N, <vector>) | 在 (0, N * 100%) 中样本的分布次数,类似于 Histogram 的概念 |
3.2 聚合操作理解
这里总结一下聚合操作大概的含义:
- 通过 without 与 by 对即时向量中所有样本过滤/保留 label;
- 按照剩余的 label 进行分组,label 值相同的为同一组;
- 按照组的维度,对每组样本进行聚合操作;
- 最后按照组得到了新的即时向量;
4 PromQL 运算符
4.1 算术运算符
算术运算符对值进行算术运算,目前包含 6 种算术运算符:
| 运算符 | 描述 |
|---|---|
| + | 相加 |
| - | 相减 |
| * | 相乘 |
| / | 相除 |
| % | 求余 |
| ^ | 幂等运算 |
-
标量 与 标量 -> 标量
1 2 3(5+1)*3 scalar 18 -
即时向量 与 标量 -> 即时向量
对即时向量中每个样本会与标量进行算术运算,因此得到一组新的值的即时向量。
1 2 3 4 5 6node_disk_read_bytes_total/1024/1024 {device="dm-0", instance="localhost:9101", job="prometheus"} 26745.40966796875 {device="dm-1", instance="localhost:9101", job="prometheus"} 3.28515625 {device="dm-2", instance="localhost:9101", job="prometheus"} 2623.3681640625 {device="sda", instance="localhost:9101", job="prometheus"} 29390.4736328125 -
即时向量 与 即时向量 -> 即时向量
两个即时向量进行算术运算时,会遍历左边即时向量中样本,按照 label 完全匹配右边即时向量样本。如果找到匹配的样本,那么进行值的运算,否则直接丢弃样本。
1 2 3 4 5 6node_disk_read_bytes_total+node_disk_written_bytes_total {device="dm-0", instance="localhost:9101", job="prometheus"} 700855357952 {device="dm-1", instance="localhost:9101", job="prometheus"} 3444736 {device="dm-2", instance="localhost:9101", job="prometheus"} 240470945280 {device="sda", instance="localhost:9101", job="prometheus"} 941364913152
4.2 关系运算符
关系运算符用于值之间的大小比较,目前包含 6 种关系运算符:
| 运算符 | 描述 |
|---|---|
| == | 相等 |
| != | 不等 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
-
标量 与 标量 -> 标量 0(false)/1(true)
标量之间使用关系运算符必须加上 bool 修饰符。
1 2 399 >= bool 80 scalar 1 -
即时向量 与 标量 -> 即时向量
对即使向量使用关系运算是用于筛选样本的。对即使向量的每个样本,会去比较标量。如果比较结果为 true 那么就保留样本,否则就会丢弃样本。
1 2 3 4 5node_disk_write_time_seconds_total >= 100 node_disk_write_time_seconds_total{device="dm-0", instance="localhost:9101", job="prometheus"} 118100.283 node_disk_write_time_seconds_total{device="dm-2", instance="localhost:9101", job="prometheus"} 10610.281 node_disk_write_time_seconds_total{device="sda", instance="localhost:9101", job="prometheus"} 88011.634 -
即时向量 与 即时向量 -> 即时向量
两个即时向量之前的关系运算,会遍历左边即时向量中样本,按照 label 完全匹配右边即时向量样本。如果找到匹配的样本,那么进行值的比较,否则直接丢弃样本。
label 完全匹配的样本比较如果结果为 true,那么保留样本,否则删除样本。
1 2 3 4 5node_disk_written_bytes_total > node_disk_read_bytes_total node_disk_written_bytes_total{device="dm-0", instance="localhost:9101", job="prometheus"} 673182207488 node_disk_written_bytes_total{device="dm-2", instance="localhost:9101", job="prometheus"} 237730660864 node_disk_written_bytes_total{device="sda", instance="localhost:9101", job="prometheus"} 910928728576
4.3 向量匹配
之前看到,两个即时向量之间做运算时,都是遵循 label 完全匹配的样本进行计算。这种即时向量的匹配规则称为 向量匹配。
Prometheus 提供了两种向量匹配模式:
-
one-to-one两个即时向量运算时,除了 name label,其他 label 完全匹配的样本进行计算。
可以使用关键字 on 指定用于匹配的 label,或者使用关键字 ignoring 忽略指定的 label.
-
many-to-one和one-to-many多对一和一对多匹配模式,可以理解为一个样本匹配到多个样本的 label。通过 group_left 或 group_right 修饰符明确指定哪个向量具有更高的基数。
4.4 逻辑运算符
逻辑运算符用于向量与向量之间,产生一个新的向量。Prometheus 提供了三种逻辑运算符:and、or、unless。
-
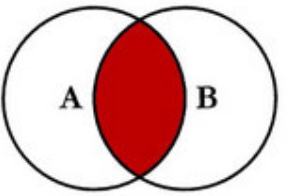
andand 逻辑运算符对两个即时向量进行交集运算。新的即时向量中包含 vector1 完全匹配 vector2 的样本。

-
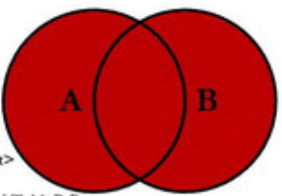
oror 逻辑运算符对两个即时向量进行并集运算。新的即使向量中包含 vector1 的所有原始样本,以及 vector2 中不与 vector1 完全匹配的样本。
-
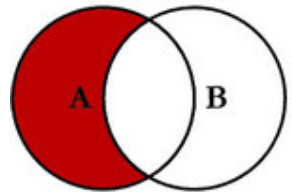
unlessunless 逻辑运算符对两个即时向量进行差集运算。新的即使向量中,只包含 vector1 独有的样本。
5 PromQL 函数
5.1 数学函数
-
abs(v vector)
输入即时向量,返回其每个值的绝对值。
-
sqrt(v vector)
对即时向量的每个样本值进行平方根。
-
round(v vector)
即时向量每个样本值四舍五入到最近的整数。
-
clamp_max(v vector, max scalar) 和 clamp_minx(min scalar)
对即时向量每个样本的值设置上限和下限。
5.2 时间函数
-
time()
查询的计算时间以秒为单位返回。
-
时钟和日历类函数
5.3 标签操作函数
-
label_replace(v vector, dst_label string, replacement string, src_label strig, regex string)
对即时向量 v,将正则表达式 regex 与 src_label 标签的值进行匹配。如果匹配,则将 dst_label 标签的值(不存在会添加)替换为 replacement 指定的。
-
label_join(v vector, dst_label string, separator string, src_label string, src_label_2 string …)
label_join 使用分隔符 separator 将所有 src_label 的值连接在一起,变为 dst_label 的值。
5.4 Counter 指标增长率
-
increase(v range-vector)
increase 函数只能对 counter 类型的区间向量。其获取区间向量中第一个和最后一个样本,并返回其增长量。
-
rate(v range-vector)
rate 函数只能对 counter 类型的区间向量调用。用于计算区间向量中时间序列每秒的平均增长率。
-
irate(v range-vector)
irate 函数计算区间向量中时间序列的每秒增长率。
5.5 Gauge 指标趋势变化预测
-
predict_linear(v range-vector, t scalar)
predict_linear 基于区间向量,使用简单的线性回归预测时间序列 t 秒的值,从而对时间序列的变化趋势做出预测。
6 注意事项
6.1 Stale 机制
Prometheus 使用 Stable 机制来表示哪些不再提供的 Time Series。当 Time Series 被标记为 Stable 或者在最新的时间点前 5min 内找不到任何样本的话,在图表上该 Time Series 会消失。
具体逻辑如下:
- 如果某个 Target 不再暴露新的 Sample,那么改 Time Series 会被标记为 Stable
- 如果 Target 被移除,那么不久后相关的 Time Series 会被标记为 Stable
- 如果标记为 Stable 的 Time Series 又产生了新的 Sample,那么 Time Series 会变回 Normal 状态
- 如果 Sample 带有了时间戳,那么不会应用 Stable 机制,而是 Time Series 有着 5min 的阈值时间
这也意味着,如果某个 Time Series 停止产生了新的 Sample,那么在 5min 内还是可以查询到数据的。超过 5min 后,查询 Time Series 就不会返回任何数据。