Prometheus 数据模型
1 数据模型
Prometheus 保存的所有数据都是 时间序列 数据,也就是每个数据会带有一个时间戳。
通过图表可以理解其模型:
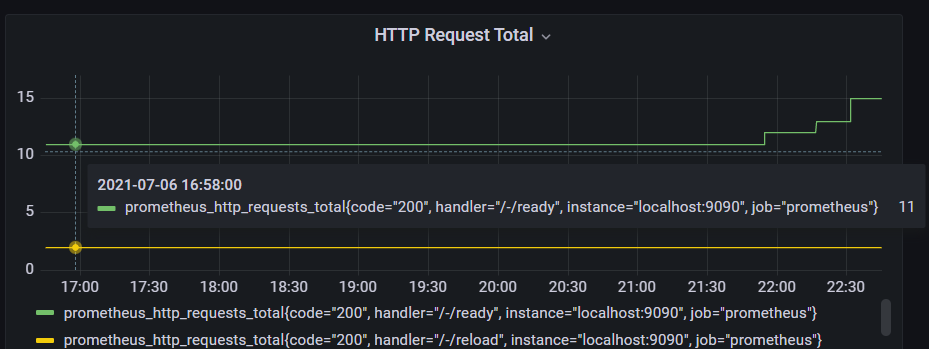
Metric- 这个统计项,由 Metric Name 表示Metric Name+Labels- 统计项下的一个数据流,图中的一条线。其组合也称为NotationSample- 数据流中的某个数据,也就是图中的某个点
1.1 Metric
Metric 定义了某个监控指标,都由如下格式表示:
|
|
该格式标识也被称为 Notation。
Metric name 表示监控项的含义,Labels 反映了样本的特征维度:
|
|
可以看到,Labels 是不同值的组合,都是一个 Metric 实例化。因此 Metric name 与 Labels 的组合才代表一个唯一的数据。
其中,__ 作为前缀的 label 是系统保留的,只能在系统内部使用。例如 Prometheus 底层实现中指标名称实际上是以 __name__=<metric name> 形式保存的:
|
|
1.2 Sample
Sample 为样本,可以理解为某个采集项某次采集的数据。按照时间排序的 Sample 形成了实际的数据序列数据列表。
每个 Sample 包含三个部分:
- metric - metric name 与当前样本的 labelsets
- value - 采集的数据,float64
- timestamp - 采集数据的时间,ms
Prometheus 会按照时间顺序来存储 sample,如果 sample 不是顺序收集的,会将其丢弃。
2 Metric 类型
目前,Prometheus 提供了 4 种 Metric 类型。
- Counter
- Gauge
- Histogram
- Summary
2.1 Counter
Counter 代表一个累加数据,通常用于跟踪事件次数,累计时间等。
其特点如下:
- 值只能从 0 开始增加,不能减少。
- 重启进程后,只会重置为 0。
Counter 适用于统计累加值。例如下面统计的是宿主机的 CPU 时间:
|
|
2.2 Gauge
Gauge 反映一个瞬时测量值,其值可能随着时间变化上下波动。
其特点如下:
- 测量值是瞬时值,可以任意变化。
- 重启进程后,会被重置。
Gauge 是适合记录无规律变化的数据。例如机器的负载值,每时每刻都在变化。
|
|
2.3 Histogram
Histogram 表示直方图,会在一段时间范围内对数据进行采样,并将其计入 bucket 中。
histogram 中有三类值:
- bucket:值小于 “le”(less)下,统计到的数据次数
- sum:统计值的累计和
- count:统计次数
看个例子,下面数据表明了对于 / 的 HTTP 请求的:
|
|
-
bucket
le=“0.1” - 请求处理时间小于 0.1s 的次数为 1 次
le=“0.2” - 请求处理时间小于 0.2s 的次数为 1 次
…
le="+Inf" - 请求处理时间小于 +Inf 的次数为 1 次
-
sum
所有请求的处理实际的总和为 0.000184525
-
count
统计的请求次数为 1 次
可以看到,对于 bucket 的统计结果是累计的。
2.4 Summary
summary 为概率图,包含了各百分比样本的值,也就是样本的值的分布区间。
summary 包含三类数据:
- bucket:百分比范围样本的值,“quantile” 表示百分比
- sum:统计值的累计和
- counter:统计次数
看个示例,下面数据表明了所有 wal_fsync 操作的耗时分布区间:
|
|
-
bucket
quantile=“0.5” - 50% 的 wal_fsync 操作耗时小于 0.012352463
quantile=“0.9” - 90% 的 wal_fsync 操作耗时小于 0.014458005
quantile=“0.99” - 99% 的 wal_fsync 操作耗时小于 0.017316173
-
sum
所有 wal_fsync 操作耗时总和 2.888716127000002
-
count
统计 wal_fsync 操作 216 次
可以看到,对于 bucket 的统计结果是累计的。
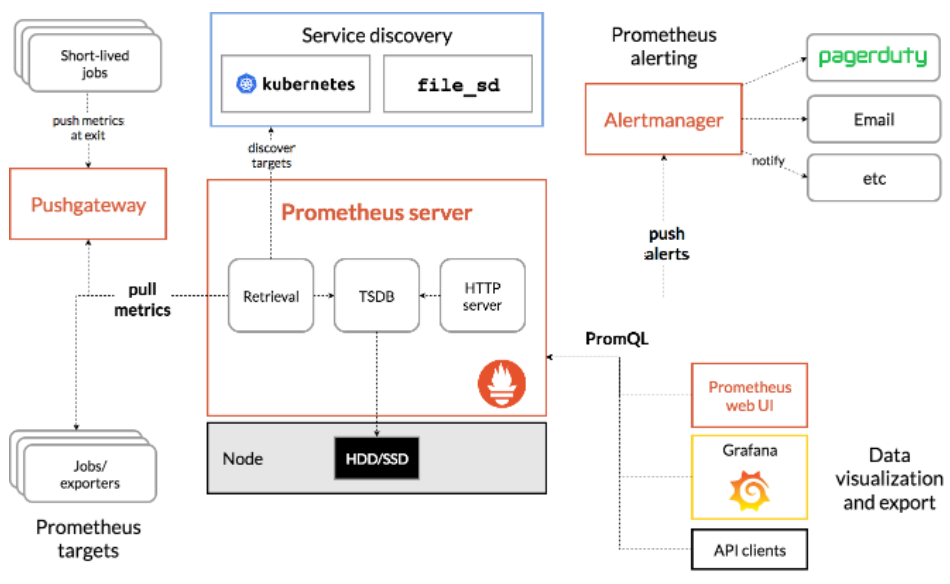
3 架构
完整的 Prometheus 生态架构图如下:
-
Prometheus Server
以 Pull 方式收集各个 Instance 的 Metric 数据,并保存在自身的时序数据库中。
-
Exporter
用于输出被监控组件的 Metric 信息的 HTTP 接口统称为 Exporter,例如 MySQL Exporter 提供 HTTP 查询接口用来采集 MySQL Metric 信息。
Prometheus Server 会根据 Job 来调用 Exporter 的接口采集信息。
-
Pushgateway
Prometheus Server 仅仅支持 Pull 方式拉取数据,如果需要支持 Push 方式推送数据,或者服务没有可暴露的 HTTP 接口(例如一些客户端仅仅只能靠 Push),那么需要 Pushgateway 作为中转临时存储。
程序将 Metric 信息推送给 Pushgateway,Pushgateway 会保存这些 Metric 信息。异步地,Prometheus Server 会定期从 Pushgateway 拉取 Metric 信息并保存。
-
Alertmanager
Prometheus Server 支持直接配置告警规则,当告警触发时,会将告警信息推送到 Alertmanager。AlertManager 进一步对数据去重过滤等处理,然后路由到不同的通知软件。
-
Granafa
Prometheus 用于存储 Time Series 数据,Grafana 通过查询 Prometheus 将这些数据可视化的展示出来。
参考
- 官方文档:CONCEPTS
- Blog:一文搞懂 Prometheus 的直方图