Prometheus 基础
1 Configuration
Prometheus 大多数特性都是通过配置文件传入的,通过参数 --config.file 指定配置文件:
|
|
Prometheus 也支持动态重新加载配置文件,可以通过发生 SIGHUP 信号或者向 /-/reload HTTP 接口发送 POST 请求重新加载配置文件。
Prometheus 配置项大致分为:
-
global - 包含一些全局的配置
1 2 3 4 5 6global: scrape_interval: 1m # 采集 metrics 的默认周期(默认值 1m) scrape_timeout: 10s # 采集 metrics 的超时时间(默认值 10s) evaluation_interval: 1m # 计算 Prometheus Rule 的周期(默认 1m) external_labels: {} # 将 metric 传给其他组件时添加的 label query_log_file: <path> # PromQL 查询的记录日志 -
rule_files - 指定需要加载的 Prometheus Rule 的文件路径
1 2 3rule_files: - file1 - file2 -
scrape_configs - 配置需要采集的目标,参考 Job 和 Instance
-
alerting - 告警相关配置
1 2 3 4 5alerting: alert_relabel_configs: <relabel> # relabel 相关配置 alertmanagers: # 指定发生 alert 的目标 - static_configs: - targets: ["192.168.186.7:9093" ] -
remote_write / remote_read - 远程存储配置,参考 远程存储
2 Job 和 Instance
在 Prometheus 中,任何被采集的目标(往往是一个 IP:Port)被称为 Instance,也被称为 Target。而将相同采集项进行分组,每个组就称为 Job。
看下 prometheus.yml 配置文件来理解这个概念:
|
|
job_name描述了一个 Job。示例中分别表示采集 Prometheus 与 Node。static_configs.targets中就表明了需要采集的 Instance。
Prometheus 拉取样本时,"job" 与 "instance" 两个 Label
|
|
2.1 Meta Label
对于每个 Instance,Prometheus 有一些隐藏的 Meta Label。这些 Label 格式常常为 __<label>__ 或者 __<meta-label>。
在 Prometheus UI 的 Targets 页面中能看到这些 Meta Label:
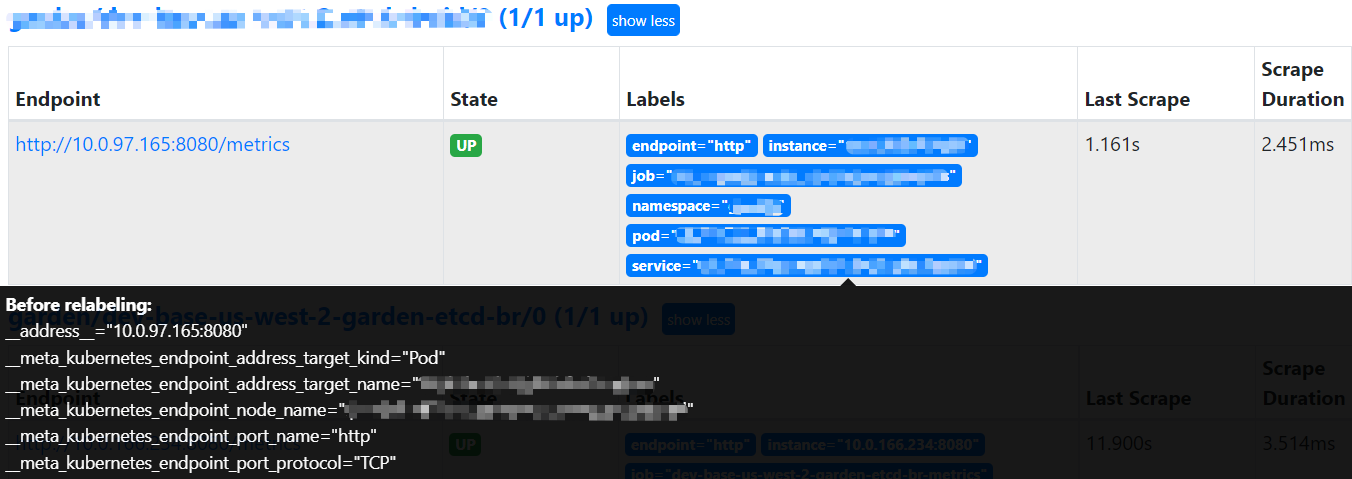
不同类型的 Target 有着不同的 Meta Label。一些通用的 Meta Label 为:
__address__: localhost:9100- Target 地址__metrics_path__: /metrics- 采集 Metrics 的 HTTP Path__scheme__: http- 采集 Metrics 的协议
默认下,Meta Label 不会添加到 Metric 中。不过有时候我们在 Relabel 配置中可以使用 Meta Label 输出更多的信息。
2.2 Relabel
Prometheus 许多地方都可以配置 relabel,即采集到的 Sample 的 Label 进行二次处理。所有的 relabel 相关配置都采用以下格式:
|
|
目前支持的 action 有:
-
replace- 对 Label Value 处理后,添加或覆盖 Label(不删除原有 Label)对
source_labels拼接后的 Value 按照regex进行处理,接着使用replacement进行 Value 替换,新的值使用target_label作为 Label Key。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16# {__address__="127.0.0.1", url="https://prometheus.io"} # To # {addr="127.0.0.1", domain="prometheus.io", "__address__="127.0.0.1", url="https://prometheus.io"} relabel_configs: - source_labels: # 变更 Label "__address__" 为 "addr" - "__address__" regex: "(.*)" target_label: "addr" action: replace replacement: $1 - source_labels: # 提取 URL 中的 Domain - "url" regex: "(.*)://(.*)" target_label: "domain" action: replace replacement: $2 -
lowercase/uppercase- 将 Label 变为小写或者大写。 -
keep- 丢弃 Label Value 无法匹配regex的 Sample对
source_labels拼接后的 Value 按照regex进行匹配,如果无法匹配会丢弃该 Sample。1 2 3 4relabel_configs: - source_labels: [container] # 仅仅接受 Label 包含 "container=manager" 的数据 regex: 'manager' action: keep -
drop- 丢弃 Label Value 匹配regex的 Sample对
source_labels拼接后的 Value 按照regex进行匹配,如果匹配会丢弃该 Sample。1 2 3 4relabel_configs: - source_labels: [container] # 过滤 Label 包含 "container=manager" 的数据 regex: 'manager' action: keep -
labelmap- 对所有 Label Name 进行regex处理,添加新的 Label对所有的 Label Name 执行
regex(所以不需要指定source_labels),接着使用replacement得到新的 Label Name。与
replace操作相比,仅仅处理 Name 不处理 Value。1 2 3 4 5 6# {__node_label_region=us-west-2, __node_label_name=node-1} # To # {region=us-west-2, name=node-1, __node_label_region=us-west-2, __node_label_name=node-1} relabel_configs: - regex: '__node_label_(.+)' action: labelmap -
labeldrop- 对所有 Label Name 进行regex处理,丢弃匹配到的 Label与 labelmap 操作相比,是执行 Label 的删除。
1 2 3 4 5 6 7 8# {region=us-west-2, node_name=node-1, addr="localhost"} # To # {addr="localhost"} relabel_configs: - regex: 'region' # 丢弃 Name 为 "region" 的 Label action: labeldrop - regext: 'node_(.*)' # 丢弃 Name 为 "node_xxx" 的 Label action: labeldrop -
labelkeep- 对所有 Label Name 进行regex处理,仅保留匹配的 Label1 2 3 4 5 6# {region=us-west-2, node_name=node-1, addr="localhost"} # To # {region=us-west-2} relabel_configs: - regex: 'region' # 仅仅保留 Name 为 "region" 的 Label action: labelkeep -
hashmod- 对 Label Value 进行 Hash 计算,添加 Value 为哈希值的 Labelhashmod将具有相同 Label 的 Sample 添加了一个分类项,进而能够按照哈希值进行分散处理,用以提高性能。1 2 3 4 5 6 7 8 9 10 11 12# {__address__="127.0.0.1"} # To # {__address__="127.0.0.1", hash_value="2"} # # {__address__="127.0.0.4"} # To # {__address__="127.0.0.1", hash_value="4"} relabel_configs: - source_labels: [__address__] # 对 "__address__" Label 的 Value 进行 Hash,作为新的 "hash_value" Label modulus: 4 target_label: hash_value action: hashmod
存在多个 Relabel 配置时,会按照顺序执行各个 Relabel 操作。例如,我们要实现将两个 Label 替换为一个新的 Label 时,就可以用 replace 与 labeldrop 的组合:
|
|
labeldrop 和 labelkeep 会对 Label 进行删除,因此需要注意删除后 Metric 的 Label 还是唯一的。2.3 Label 冲突
采集数据后,Prometheus 会对样本的 Label 进行处理,例如添加 job 或 instance Label,Relabel 处理。这时如果新添加的 Label 已经存在于原始数据时,由 honor_labels 配置来决定如何处理冲突。
|
|
当 honor_label: false 时,原始的 Label 会被重命名为 exported_${label},而 Prometheus 添加的 Label 保留原始名称。
当 honor_label: true 时,原始的 Label 会被保留,而 Prometheus 不会添加 Label。
2.4 内置 Metric
对于每个被采集的 Instance,Prometheus 也会内置一些统计数据。
-
up - 如果 Instance 能够被正常采集,那么值为 1,否则为 0
1up{instance="localhost:9090", job="prometheus"} 1 -
scrape_duration_seconds - 采集 Instance 累计的使用时间
1scrape_duration_seconds{instance="localhost:9090", job="prometheus"} 0.006962203 -
scrape_samples_post_metric_relabeling - Instance 的采集数据被 relabel 后,剩余的采集数量累计
1scrape_samples_post_metric_relabeling{instance="localhost:9090", job="prometheus"} 723 -
scrape_samples_scraped - 从该 Instance 采集数据的次数
1scrape_samples_scraped{instance="localhost:9090", job="prometheus"} 723
3 Prometheus Rule
Prometheus Rule 中支持两种 Rule:Record Rule 与 Alert Rule。两种 Rule 都是通过 Rule 文件或者目录提供给 Prometheus。
|
|
3.1 Record Rule
Record Rule 可以让 Prometheus 周期性执行一些表达式,并允许将执行结构保存为一组新的 Time Series。
Record Rule 使得让一些计算量比较大的表达式预先执行,而不用每次需要时执行查询。
一个 Record Rule 文件如下所示:
|
|
每个 Record Rule 包含如下配置:
- record - 输出的新的 metrics 的名称
- expr - record 计算使用的 PromQL
- labels - 添加到 record 上的 label
3.2 Alert Rule
Alert Rule 让 Prometheus 会周期性的执行指定的 PromQL,满足条件后就会发送 Alert 给 Alertmanager。
一个 Alert Rule 文件如下所示:
|
|
Prometheus 所有的 Alert Rule 是按分组来管理的,每组包含多个相关的 Alert Rule。
一个 Alert Rule 包含如下配置:
- alert - alert 的名称
- expr - alert 计算使用的 PromQL
- for - (可选)
expr满足持续多长时间后,才会发送告警 - labels - 添加到 alert 的 label
- annotations - 设置 alert 的描述信息,发送时会作为参数一起发送
3.2.1 Template
在 Alert Rule 中,labels 和 annotations 配置可以使用 Golang 的模板语法,以使用一些 PromQL 执行结果的信息。
目前支持的模板变量为:
{{ $labels.<label_name> }}- 读取 PromQL 执行结果的某个 label 的值;{{ $value }}- 用于获取 PromQL 执行的结果值;
3.2.2 触发规则
配置 Alert Rules 后,Prometheus 就会周期性执行 PromQL 计算是否触发告警。
触发 Alert 会经过三种状态:
- Inactive - 没有满足条件,告警处于未激活状态
- Pending - 首次触发告警规则时,但是并没有满足
for配置项的持续时间,告警会处于 PENDING 状态 - Firing - 已经触发告警,并满足了持续时间。处于 Firing 状态下,Prometheus 会持续将告警发送
4 Storage
Prometheus 默认使用本地磁盘存储 Time Series,不过也支持与其他远端存储集成。
4.1 Local Storage
4.1.1 存储格式
所有的 Sample 会以 2h 间隔分组为一个个 Block。也就是说,Prometheus 会在内存中保存当前的 Block,超过 2h 后就将 Block 持久化,然后在内存中保存新的 Block。
每个 Block 持久化对应一个目录:
|
|
每个 Block 目录的结构如下:
|
|
-
chunks子目录子目录包含一个或多个 Segment 文件,每个 Segment 由多个 Sample 组成。
一个 Segment 默认最大为 512MB。
-
meta.json文件元信息文件,内容为该 Block 的元信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17{ "ulid": "01GK97WG0RB4QSXW0MGJ5ZC5WG", "minTime": 1669968000048, "maxTime": 1669975200000, "stats": { "numSamples": 129635173, "numSeries": 731887, "numChunks": 1162259 }, "compaction": { "level": 1, "sources": [ "01GK97WG0RB4QSXW0MGJ5ZC5WG" ] }, "version": 1 } -
index文件索引文件,将 Metric Name 与 Label 映射到
chunks目录中的 Sample。 -
tombstones文件被删除的 Sample 会记录在
tombstones文件中,而不是直接修改 Segment 文件。 -
wal目录Prometheus 抓取数据后,会先写到内存中的 Block,不会直接持久化。Prometheus 通过 WAL 来保证崩溃时不会丢失这些数据。
WAL 日志文件会以 128MB 的分段大小存储在
wal目录中。这些文件包含未被 compact 的原始数据,因此它们通常比 Block 文件大。Prometheus 会保留至少三个 WAL 日志文件,高流量的服务器可能会保留三个以上的 WAL 文件,以保留至少两个小时的原始数据。
如果想要知道更加细节的文件内容格式,参考 TSDB format。
4.1.2 Compaction
Compaction 指定是对持久化的数据进行压缩:最老的每 2h 的 Block 会被周期性的 Compact 为一个更长时间的 Block。
Compact 后的 Block 包含的数据的时间跨度最大可能为(两者之中的最小值):
- 配置的 Retention Time 的 10%
- 31 天
4.1.3 存储配置
本地存储相关的命令参数:
--storage.tsdb.path- Prometheus 写入数据的目录,默认为 /data。--storage.tsdb.retention.time- 时间保留策略,配置保留旧数据的时间,默认为 15d。--storage.tsdb.retention.size- 大小保留策略,配置存储数据的最大字节数。到达阈值时,最旧的数据将首先被删除。注意,wal目录和chunks_head目录也会被计入存储数据大小,但是只有 Block 才会被删除。--storage.tsdb.wal-compression- 对 WAL 日志启动压缩
4.1.4 运营相关
每个 Sample 存储大小大致为 1-2 字节。因此可以用以下公式粗略的计算 Prometheus 需要的存储大小:
|
|
如果本地存储损坏时,最佳解决方案是关闭 Prometheus,然后删除整个存储目录。你也可以尝试删除单个 Block 或者 WAL 目录解决问题,当然删除一个 Block 意味着丢失 2h 数据。
如果通知配置了 retention.time 或者 retention.size,那么两个保留策略都会生效,Prometheus 会在后台删除过期的 Block。
4.2 Remote Storage
Prometheus 没有试图在本身解决存储的可用性的问题,而是提供了一组与远程存储集成的 API。
Prometheus 通过三种方式使用远程存储:
- 支持将 Sample 以标准格式写入远程存储的 URL
- 支持从其他 Prometheus 接收标准格式的 Sample
- 支持从远程存储的 URL 读取标准格式的 Sample
远程存储的整体架构如下:

Prometheus 不会直接对接各个存储,而是定义了 Read/Write 接口,通过实现各个 Adapter 来将读写请求转化为远端存储的读写请求。
目前已经支持的远程存储见文档:Integrations documentation。
4.2.1 远程存储配置
remote_write 配置项用于配置将 Sample 写入远程存储:
|
|
其中,queue_config 见 远端写入特性。
remote_read 配置项用于配置从远程存储读取 Sample:
|
|
4.2.2 远端接口协议
Prometheus 通过 HTTP POST + Protobuf 编码 方式读或者写远端存储 URL,未来可能采取 gRPC(HTTP2) + Protobuf 方式。
接口定义如下:
|
|
每个远端存储的 Adapter 通过实现 Read/Write 接口来对接到 Prometheus。官方提供了多个 Adapter Example。
4.2.3 远端写入特性
Prometheus 写入 Adapter 的接口是同步地,因此为了让 Adapter 协调不同的性能的远程存储,Prometheus 会在本地通过队列的方式暂存需要写入的 Sample,然后进行异步地写入。并且,还可以将多次写请求合并,以减少写入请求次数来提高性能。
对于一个远程存储 Adapter,Prometheus 会启动多个队列并行地从 WAL 中读取,并行写入 Adapter,这个队列也被称为 Shard。每个 Shard 队列会单独启动一个 Goroutine 负责发生数据。
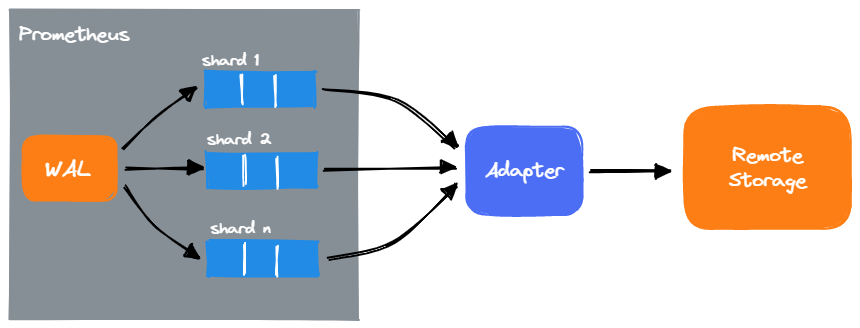
Prometheus 会每个 10s 动态地调整 Shard 队列的数量。调整的依据是:根据上一个周期 Adapter 接受的 Sample 数量,以及目前队列中的 Sample,增加或减少 Shard 队列数量。
对应,Prometheus 提供了 Shard 相关的配置,位于 queue_config 配置项:
|
|