K8s 编程 - Operator Programming Notes
下面是作为 Operator 初学者自己总结的一些经验,纯属个人随意总结,没有任何正确性可言。
使用 Status 传递过程式操作状态
过程式操作指的是 Upgrade Scale 这样的操作,也就是触发后需要 Operator 进行持续性的操作。
过程式操作对于 Operator 就是:根据当前的状态,进行操作,以逐步变为期望状态。我们把更新的 Spec 中配置称为 DesiredConfig,当前已经存在的资源配置称为 CurrentConfig。
大多数情况下,在 Resource 字段上要能够知晓以下操作的阶段:
- NotStarted - 操作还未开始
- InProgress - 操作执行中,可能还需要操作的进度
- Done - 操作完成
- Unknown (optional) - 观测出现异常
为了能够展示出操作的字段,我们可以通过以下配置传递信息。以 StatusfulSet 为例来说明:
|
|
Spec.DesiredConfig- 对应spec.templateStatus.CurrentConfig- 对应status.currentRevisionStatus.DesiredConfig- 对应status.updateRevisionStatus.CurrentConfigCount- 对应status.currentReplicasStatus.DesiredConfigCount- 对应status.updatedReplicasSpec.Generation- 对应metadata.generationStatus.ObservedGeneration- 对应status.observedGeneration
通过这些字段,我们可以判断出操作所处的阶段:
|
|
使用标志位互斥操作
在复杂的 Operator 编写时,往往有一些操作是需要互斥的,例如 Initialize 过程中不允许执行 Scale 或者 Upgrade 操作,或者 Scale 与 Upgrade 也是不能同时进行的。
互斥操作实现很简单,先获取 “锁”。在 Kubernetes 中,更新 Resource 是原子性的,因此我们可以通过 Resource Status 中的某个字段来实现锁。
代码示例如下:
|
|
可以看到,上面通过 Flag 作为操作前的必要条件,并且分离的条件判断与操作。
Read 与 Write 分离
Operator 编写中,往往需要先获取一些资源,然后根据资源进行操作。Read 与 Write 分离指的就是:“读取资源” 与 “进行操作” 的分离。
|
|
Read 与 Write 分离的最大好处是:Resource 只需要获取一次,后面各个 Operate 都可以复用这一个 Resource,并且所有操作是看到的都是同一个份 Resource,不会有 Resource 差异导致不同行为的问题。
不仅仅是 “读取资源” 与 “进行操作” 的分离,在 Operate 时,可以实现 “判断” 与 “操作” 分离。
|
|
“判断” 与 “操作” 分离使得整体的 Operate 分为了清晰的步骤,更容易阅读与扩展。如果 Operate 之间互斥,可以使用 如何使用标志位互斥 中描述的代码。
为何需要 Last Applied Configuration
在 kubectl apply 实现中,默认的 Client Side Apply 会在 Resource 的 Annotation last-applied-configuration 记录上一次的 Apply Config。当下一次 Apply 时,通过使用 Three-way Merge 来生成 Patch 请求,进而更新 Resource。
为什么需要额外记录一个 Annotation 记录,而不是直接使用当前的 Object 与 Apply Config 来生成 Patch 请求?
我们通过一个例子说明,如果直接使用 Object 来进行 Diff 会发生什么:
- Original - 为我们第一次更新的 Object;
- Current - 当前的 Object;
- Modified - 我们本次期望更新的 Object;
-
第一次使用 Apply 后,得到下面的 Object。这时候
fieldA和fieldB都是由 Apply 来更新的。1 2 3 4kind: Object spec: fieldA: aaa fieldB: bbb -
如果该 Object 另外字段也会由其他 Controller 管理,那么可能其他 Controller 更新了
fieldC字段。1 2 3 4 5kind: Object spec: fieldA: aaa fieldB: bbb fieldC: ccc -
但是,
fieldC字段的更新并不会体现在你的 Apply Config 中,这时候你再次 Apply 就会导致fieldC字段的丢失。1 2 3 4 5kind: Object spec: fieldA: aaa fieldB: bbb # fieldC: ccc # deleted by apply
问题最关键地点在于,Apply 的语义是 Update(而不是 Patch),所以需要知道 Apply 管理的是哪些字段,从而不影响其他的字段。因此需要额外的 Annotation 来记录管理的哪些字段。
不过,也许你也有另一个问题,为什么进行 Three-way Merge,而不是直接比较 Original 与 Modified?
在通过一个例子说明:
-
第一次使用 Apply 后,得到下面的 Object。这时候
fieldA和fieldB都是由 Apply 来更新的。1 2 3 4 5# Original kind: Object spec: fieldA: aaa fieldB: bbb -
其他 Controller 管理,可能也会管理
fieldA字段,将其更新了。1 2 3 4 5# Current kind: Object spec: fieldA: AAA fieldB: bbb -
通过 Original 与 Modified 的比较,我们并不知晓
fieldA被别人更新了,所以会将fieldA修改回来1 2 3 4kind: Object spec: fieldA: aaa # revert by apply fieldB: bbb
这就是另一个问题,Two-way merge 并不能检测出字段修改冲突,而是无脑的将其更新。Three-way merge 能够通过比较判断出字段冲突,虽然不能解决冲突,但是也能让我们知晓冲突。
最后,上面两者的原因也就是 Server Side Apply 的优点:
- 字段管理 - 明确表明了哪些字段是哪些所有者管理的,也就不需要记录 Last Applied Configuration 了。
- 冲突处理 - 如果出现多个所有者更新同一个字段,需要显式的进行冲突处理。
设计 Resource 定义之前
Kubernetes 一个极大的优势是与云计算的相辅相成。云计算在资源的创建上,有着很大的灵活性。对应地,设计 Resource 定义时我们也需要考虑好如何来适应云计算的灵活性。
Heterogeneous
Heterogeneous 指的是 Resource 定义设计时,要考虑:一个 Resource 能够支持多个 Config。
一个典型地例子是 Mutli-Domain Deployment。举个例子,我期望 Service 部署在三个 Region 各部署一个。
-
一种可选的方式是:通过 Pod Topology Spread Constraints 的功能。
但是这样一个缺点是,不能定制每个 Region 的 Pod 了,包括 Labels 或者 Annotation。
-
另一种方式是:通过 Pod Node Selector 或者 Node Affinity 功能,每个 Region 创建独特一种 Pod。
那么就要求,我的 Resource 能够支持多个 Config,类似于:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22apiVersion: myserivce.io/v1alpha1 kind: Service spec: topology: - name: region-a nodeSelector: matchExpressions: - key: node operator: In values: - zone-a config: # ... - name: region-b nodeSelector: matchExpressions: - key: node operator: In values: - zone-b config: # ...
类似地例子,如果我的 Service 需要部署多个 Component,那么最好我能够支持不同 Config:
|
|
特别是在分布式的软件中,多个 Replication 组成一个 Cluster,那么异构能解决很多问题,例如冷热问题、单点问题。
Federation
编写分布式的软件中,为了防止一个 Kubernetes 集群异常后导致整个服务不可用,可能会考虑将 Cluster 部署在多个 Kubernetes 集群中。
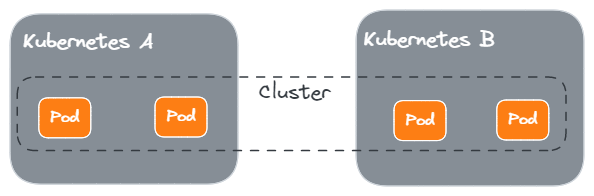
我们不考虑 Kubernetes 集群之间如何联通的问题,只关心 Operator 如何设计的问题。
一种方式是,Operator 只管理同集群的 Pod,各个 Pod 之间通过 Resource 的配置来联通:
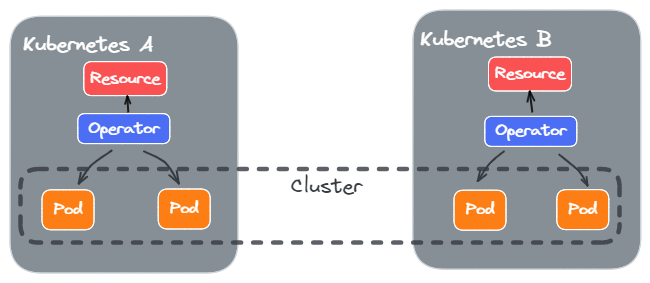
但是这样有很明显的弊端:每个 Operator 只能看到当前集群的 Pod,如果遇到多个集群 Pod 操作,如果各个 Operator 之间协调。
例如,想要升级 Cluster,那么最好的做法是 Kubernetes A 升级一个 Pod,Kubernetes B 升级一个 Pod,然后这样进行下去。但是这个在两个 Operator 之间很难管理,通常的做法引入另一个管理多个 Operator 的 Federation Opeartor。
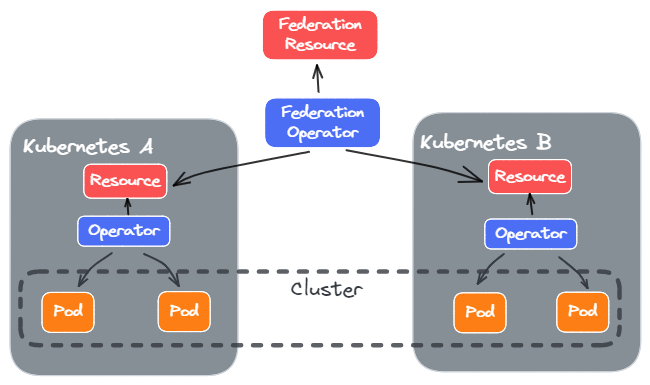
这种方式下,Resource 定义类似于:
|
|
或者,我们直接让 Operator 就作为 Federation Opeartor,能够支持多个 Kubernetes 集群部署呢。这就是另一种方式。
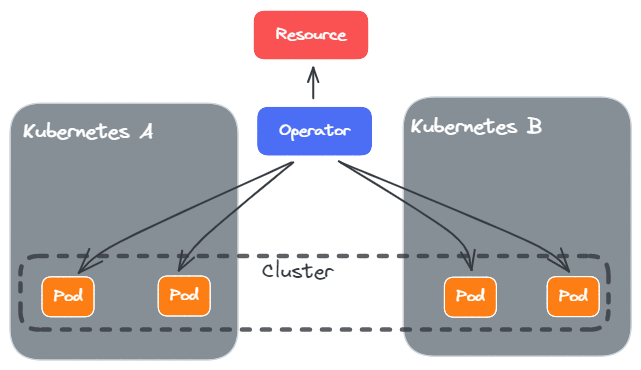
这样,我们的 Resource 定义可能类似与(看起来也是 Heterogeneous 的一种?):
|
|