Kubernetes - HPA 与 VPA
HPA 的核心原理就是就是从 Metric Server 采集指标数据,然后根据缩扩容算法进行计算,得到目标的 Pod 副本数量。当目标 Pod 副本数量与当前副本数量不同时,HPA Controller 调用指定的资源对象的 scale 操作,进行缩扩容。
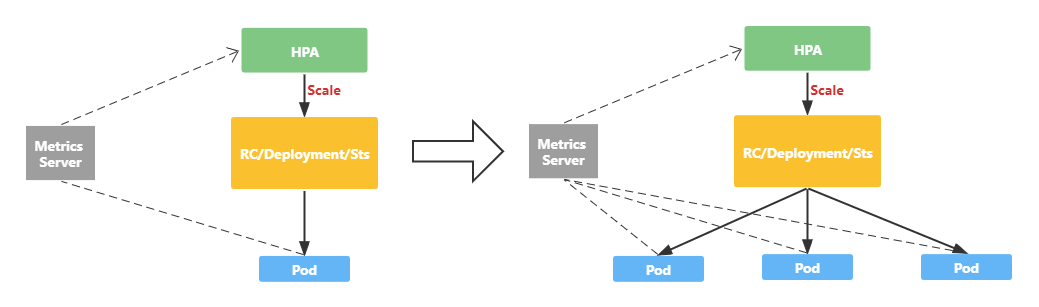
1 HPA 缩扩容算法
从最根本上看,缩扩容算法按照以下的公式来计算目标的 Pod 副本数量。
|
|
-
currentReplicas- 当前 Pod 的副本数量 -
currentMetricValue- 当前的 Metrics 值 -
metricValue- 预定义的 Metric 值
currentMetricValue 与 metricValue 可以按照固定值、平均值或者使用率的方向去计算。
-
Value -
desiredMetricValue为固定值,currentMetricValue为采集到的值 -
AverageValue -
targetAverageValue为固定值,currentMetricValue为所有 Pod Metric 的平均值 -
Utilization -
targetAverageUtilization为固定的比例,为固定值,currentMetricValue将所有 Pod 的 Metric 值求平均后除以 Metric 总和
可以设置基于多个 metric 指标计算,HPA 会对每个 metric 算出各个 desiredReplicas,然后以全部结果的最大值作为最终结果。不过,如果其中一个 metric 无法算出 desiredReplicas,那么就会跳过本次缩扩容。
1.1 容忍度
为 desiredReplicas 与 currentReplicas 比例接近于 1 时,可以设置 tolerance 值来让 HPA Controller 不进行缩扩容。
默认下,tolerance 设置为 0.1(10%),那么当 desiredReplicas 与 currentReplicas 比例在 [-10%, +10%] 区间时,不会进行自动缩扩容。
1.2 异常处理
当计算 desiredReplicas 时,如果部分 Pod 处于异常状态,那么对于这些 Pod 的数据会进行特殊的对待。
Pod 的异常状态包括:
- Pod 正在被删除(DeletionTimeStamp != nil)
- Pod 的 metric value 无法采集
- Pod 还未达到 Ready 状态(仅仅对于 CPU 指标的缩扩容使用)
对于 desiredMetricValue 的方式,所有异常的 Pod 会被忽略,不计入 currentReplicas 与算出 desiredReplicas。 对于 targetAverageValue / targetAverageUtilization,在计算平均值会使用 “保守” 地策略。
- 在需要 Scaleup 计算时,认为 Pod 的 MetricValue 比例为 0%,以减小算出的 desiredReplicas
- 在需要 Scaledown 计算时,认为 Pod 的 MetricValue 比例为 100%,以增大算出 desiredReplicas
1.3 冷却时间
HPA 计算目标副本数量时,可能因为指标的抖动导致 Pod 副本数量频繁变化。可以配置 kube-controller-manager 的启动参数 --horizontal-pod-autoscaler-downscale-stabilization 来设置两次缩扩容操作的间隔时间(默认该值为 5min)。
当然需要理解,当该参数过小时,可能导致副本数量的抖动,当该参数过大时,HPA 可能不能很好的改变副本数量。
2 Spec
HorizontalPodAutoscaler 基本的定义如下:
|
|
-
minReplicas - 定义自动缩扩容的最小副本值
-
maxReplicas - 定义自动缩扩容的最大副本值
-
scaleTargetRef - 指定 HPA 操作的资源,例如 Deployment/StatefulSet/ReplicaSet
-
metrics - 用于计算副本值的数据,支持使用 Kubernetes 集群内部数据,或者来自于 metric 数据
-
behavior - 控制缩容与扩容的行为
2.1 缩扩容的目标
HPA 在经过算法计算,需要实际进行缩扩容时,会调用定义的目标对象的 scale 接口。因此,只要实现了 scale 接口的资源都可以作为 HPA 操作的目标对象。例如 Deployment 和 StatefulSet,以及定义了 scale subresource 的 CRD。
在定义中,通过 spec.scaleTargetRef 来定义操作的目标对象。
|
|
2.2 Metric 指标
HPA 支持读取 Kubernetes 内置的或者第三方的 Metric 指标,来进行副本的计算。
HPA 会通过访问 Kubernetes APIServer 的特定接口读取 Metric 值,但是这些 Metric 的接口都不是 Kubernetes APIServer 内置的,需要用户先部署提供接口的 Custom APIServer(Aggregate APIServer)。
HPA 根据不同类型的 Metric 指标,会请求不同的接口。
-
Resource 指标 - CPU/Mem 资源相关,会请求 metrics.k8s.io 接口
Kubernetes 提供了实现 metrics-server 可以直接部署使用。
-
Custom 指标 - 自定义 Kubernetes 集群内部的指标,会请求 custom.metrics.k8s.io 接口
其他指标会提供名为 “Adapter” 作为 Custom APIServer 实现。如果想自己编写,可以参考 示例项目 开始。
-
External 指标 - 从 Kubernetes 集群外部得到的指标(例如从云厂商的数据),会请求 external.metrics.k8s.io 接口
依旧由名为 “Adapter” 的 Custom APIServer 实现。自行编写与 Custom 指标一样。
上面不同的 Metric 指标体现在 spec.metrics 字段:
|
|
其中 type 字段指明了指标的类型,不同类型的指标会使用不同的字段。
-
Resource -(Resource 指标)目标对象的 Pod 的 CPU/Mem 指标。
对于 CPU,仅支持 target 设置为
type: Utilization,来设置 CPU 的平均使用率。对于 Mem,仅支持 target 设置为
type: AverageValue,来设置 Mem 的平均使用值。1 2 3 4 5 6type: Resource resource: name: cpu target: type: Utilization averageUtilization: 60 -
ContainerResource -(Resource 指标)目标对象的 Pod 的某个 Container 的 CPU/Mem 指标。
对于 CPU,仅支持 target 设置为
type: Utilization,来设置 CPU 的平均使用率。对于 Mem,仅支持 target 设置为
type: AverageValue,来设置 Mem 的平均使用值。1 2 3 4 5 6 7type: ContainerResource containerResource: name: cpu container: application # 针对 Pod 中的 application 容器 target: type: Utilization averageUtilization: 60 -
Pods -(Custom 指标)伸缩对象的 Pod 指标,例如 metrics-server 提供 Pod 的每秒收包指标。
仅支持 target 设置为
type: AverageValue。1 2 3 4 5 6 7type: Pods pods: metric: name: packets-per-second target: type: AverageValue averageValue: 1k -
Object -(Custom 指标)一些 Kubernetes 集群的对象的指标,例如 metrics-server 提供了 Ingress 的 QPS 指标。
仅支持 target 设置为
type: AverageValue和type:Value。1 2 3 4 5 6 7 8 9 10 11type: Object object: metric: name: requests-per-second describedObject: apiVersion: networking.k8s.io kind: Ingress name: main-route target: type: Value value: 2k -
External -(External 指标)非 Kubernetes 原生对象的指标
2.3 Scaling Behavior
spec.behavior 字段用以控制 HPA Controller 进行缩扩容的行为。
|
|
其中,scaleDown 与 scaleUp 具有相同的字段,一个用于控制缩容行为,另一个控制扩容行为。
2.3.1 缩扩策略
policies 字段用于定义一个或多个缩扩策略。当指定多个缩扩策略时,会选择算出缩扩副本数最多的策略。
下面的配置等于默认的缩扩行为:
|
|
type 表示策略的控制维度,periodSeconds 表示计算该策略的时间区间,value 表示最大数值。
目前支持两种方式(type)的控制:
- Pods - 控制每次缩扩的最大允许数量
- Percent - 控制每次缩扩的最大比例
以上述配置为例,第一个策略表示 60s 内最多允许缩容 4 个副本,第二个策略表示 60s 内最多缩容当前副本数的 10%。
2.3.2 缩扩策略选择
selectPolicy 字段用于控制每次选择缩扩策略的行为,支持:
- Max -(默认)多个策略下,选择副本变化最大的策略。
- Min - 多个策略下,选择副本变化最小的策略。
- Disabled - 不进行缩或者扩
2.3.3 稳定窗口
当 Metric 持续抖动时,可以使用稳定窗口来限制副本数上下振动。缩扩算法在执行缩扩时,会考虑过去计算过的期望状态。
字段 stabilizationWindowSeconds 用于指定考虑过去多久的期望状态。
|
|
这里表示,过去 5min 的所有期望状态都会被计算。如果稳定窗口为 0 时,表明当前算法计算出缩容时会立即执行。这可以避免扩缩算法频繁的删除 Pod 又重建 Pod。
3 Status
3.1 Condition
status.conditions 字段展示了 HPA 是否能够执行缩扩,以及受到了哪些的限制。
|
|
AbleToScale表示 HPA 是否能够获取和更新缩扩信息,以及是否存在阻止缩扩的限制条件。ScalingActive表示 HPA 是否启用,以及是否能够完成缩扩计算。当为 False 时,通常为获取 Metric 出现稳定。ScalingLimited表明缩扩值是否达到了限制值(最大最小限制值)。通常这表明可能需要调整maxReplicas或minReplicas。