Kubernetes - 网络设计
1 网络模型
Kubernetes 集群中的网络是虚拟扁平的大网络,Service 与 Pod 的网络有着各自独立的一个网段,每个 Service 与 Pod 占用网段中的一个 IP。Pod 之间可以通过 IP 相互访问,不需要任何的 NAT。
网络作为基础设施有着多种多样的实现,为了适配各种网络访问,Kubernetes 集群不会负责网络的构建,只是定义 CNI 协议,由不同的 CNI Plugin 去构建网络。
为了满足基本的网络模型,Kubernetes 强制要求所有网络设施要满足:
Pod 能够与其他 Node 上的 Pod 通信,并且不需要 NAT ;Node 上的 Agent(例如 System Daemon 或 kubelet)可以和该 Node 上的所有 Pod 通信 ;
2 Container 之间的通信
Container 之间的通信指的是:一个 Pod 内的不同 Container 之间的通信。
Pod 内所有的 Container 都同属于一个 Network Namespace,Container 共享着网络设备、网络协议栈等等,可以认为 Container 处于同一个 Host 上。
因此,localhost 网络设备的通信
3 Pod 之间的通信
Pod 之间的通信指的是:Pod 中的 Container 通过 IP 直接访问另一个 Pod 中的 Container。
3.1 核心思想
在 Docker Bridge 网络 中介绍过 Bridge 网络设备可以作为同 Host 的 Container 之间的网桥,即使 Container 有着独立的 Net Namespace 也可以相互通信。
Pod 之间的网络的核心思想类似:
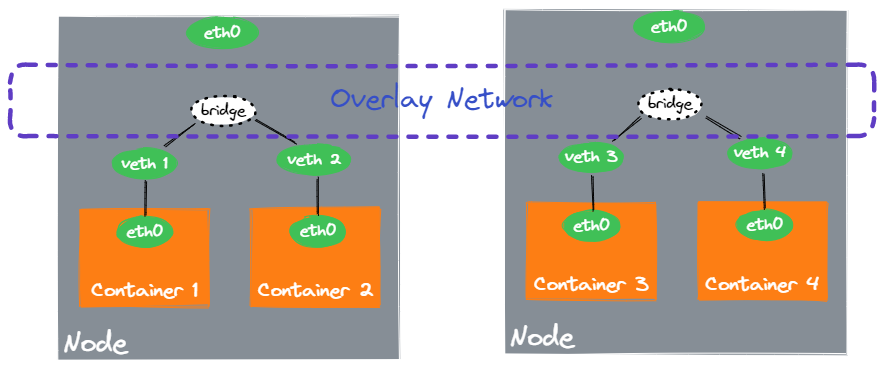
- 当同 Node 的 Pod 之间通信时,“网桥” 将数据包直接转发到对应的 Pod 对应的 Container 的 Veth 设备上。
- 当跨 Node 的 Pod 之间通信时,“网桥” 根据目标地址的网段,将数据包转发到另一个 Node 上的 “网桥”,再由 “网桥” 转发到对应 Container 的 Veth 设备上。
通过这种方式在 Node 宿主机网络上,构建出了 Kubernetes 集群的虚拟网络,称之为 Overlay Network。
3.2 基于代理的实现
我们来看最简单的容器网络实现:使用软件实现 “网桥”,来处理数据包的转发。下面以 Flannel UDP 模式为例:
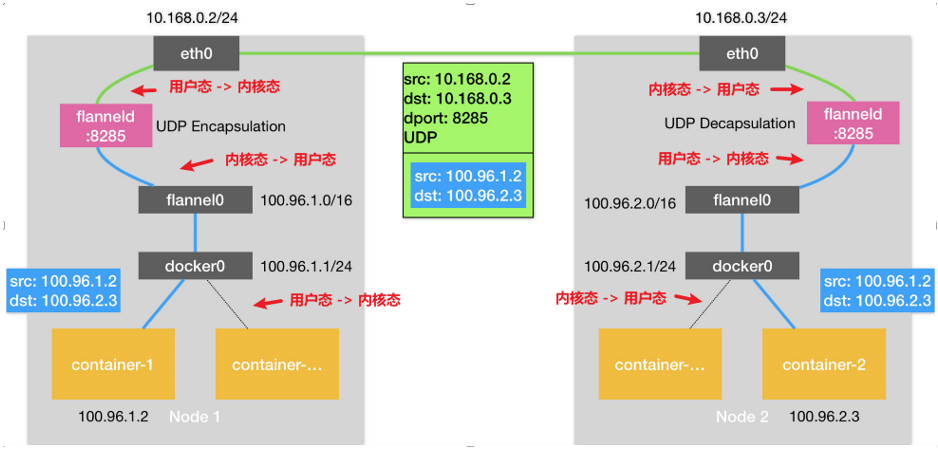
整体流程如下:
-
container-1 发送数据包(src:100.96.1.2 dst:100.96.2.3),因为是跨 Node 网段通信,因此根据默认路由交给 Node1 的 docker0 网桥。
-
docker0 是 Node 宿主机的一个网络设备,根据宿主机路由规则,将数据包转发给了 flanneld 网络设备处理。
该路由规则由 flanneld 启动后负责配置。
-
flannel0 是一个 TUN 设备,因此数据包会由 Node 上的一个程序处理,也就是 flanneld。
-
flanneld 收到 container-1 的数据包,根据包的目的地址,搜索 flanneld 记录的所有容器的 IP 网段与 Node 的路由信息,知晓其需要发送给 Node2。
flanneld 会将 IP -> Node 的映射信息保存在你 ETCD 中,因此能够根据 IP 网段知晓对应的 Node。
-
flanneld 将数据包再次封装,以 UDP 方式发送给 Node2 的 flanneld。
-
Node2 的 flanneld 收到数据包后,将其发送给 container-2 容器。根据路由规则,会从 Node2 的 docker0 网桥转发给 container-2。
可以看到,Flannel 负责的有:
- 容器网桥的管理。负责管理 docker0 与 flannel0 的管理。
- 宿主机路由规则的管理。使得数据包能正确的被转发到 flanneld 上。
- 维护网络拓步图。记录 IP 网段与 Node 的映射信息,使得能够正确的转发。
- 跨 Node 传输数据包。通过进一步的封包解包,使得容器数据包能够正确的跨 Node 传输。
但是显而易见地,这种多了一次的内核态与用户态的转换,并且 flanneld 的封包解包也会消耗很多的资源。目前 UDP 模式已经废弃。
3.3 基于三层网络的实现
在 3.2 基于代理的实现 中,由于使用软件实现网桥,因此从根本上方案性能就很差。
为此,目前主流的方案是直接在 Node 网络中就打通 Container 之间的网络。也就是 Node 网络能够支持转发 Container 网络的数据包。
在这个思路上,有着许多的方案:
-
VXLAN - 使用 VXLAN 在 Node 之间构建 “隧道”,当 Container 之间通信时,数据包由 “隧道” 处理传输到另一端。
例如 Flannel 的 VXLAN 模式。
-
Host Route - 通过配置宿主机上的 Route Table,根据 Node 负责的网段来转发到对应的 Node。
因此,这里的关键点在于:如何配置每个 Node 的 Route Table,使得能够支持转发给所有其他的 Node。
例如 Flannel 的 host-gw 模式,Calico 的 BGP 模式。
-
eBPF - 通过 eBPF 使得运行在内核态的应用程序来处理转发。
例如 Calico 的 eBPF 模式,Cilium 的 eBPF 模式。
以 Calico 的 BGP 模式为例:
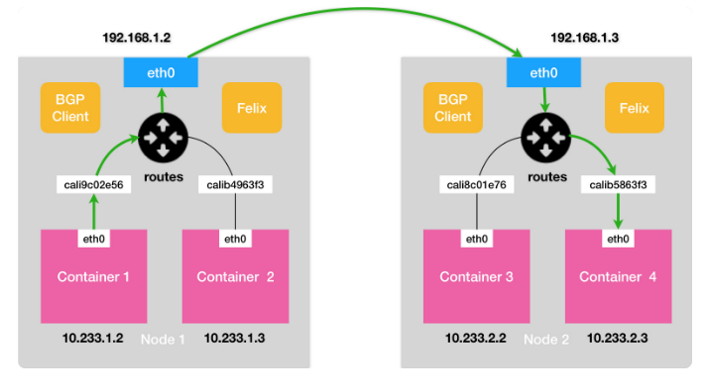
在 Node 宿主机上,Calico CNI Plugin 为每个 Container 设置一个 Veth Pair 设备:一端在宿主机上(命名为 calixxx),一端作为容器中的 eth0。
-
Inbound Rule
calixxx 设备为设置一条 Route Rule,用于接收数据包。这样发送给 Container 的数据包到达 Node 时,能够正确地被转发给 Veth Pair 设备,从而发送到 Container 中。
-
Outbound Rule
每个 Node 运行的 Felix 会负责维护 Node 的 Route Rule,将每个 Node 都会被设置一跳 Route Rule。当跨 Node 通信时,基于 Route Table 就能够将数据包转发到对应的 Node 上。
可以看到,Calico 将每个 Node 做当做边界路由器处理,互相之间通过 BGP 协议交换路由信息。每个 Node 也被称为 BGP Peer。
基于学习路由的方式不同,又分为:
-
Node-to-Node Mesh 模式
每个 Node 的 BGP Client 会和所有 Node 的 BGP Client 通信。也就是说,学习路由的方式是 P2P 的。
但是随着 Node 的增加,Node 之间的连接也会指数的增长。因此该模式一般在 100 节点的集群里使用。
-
Route Reflector 模式
该模式下,Calico 会指定一个或者一部分 Node,来和所有 Node 建立 BGP 连接。其他 Node 只要和专门的 Node 交换路由信息,就可以学习到整个集群的路由了。
3.4 跨三层网络的实现
3.2 基于代理的实现 与 3.3 基于三层网络的实现 都要求 Node 之间是可以直接访问的。当集群中 Node 不在同一个局域网时,就需要更多的配置了。
4 Pod 与 Service 之间通信
Pod 之间的通信类似于 P2P 的通信模式,Pod 与 Service 之间的通信类似于 C/S 的通信。Pod 直接访问 Service,数据路由到 Service 背后的 Pod 处理后,通过源 IP 返回数据包。
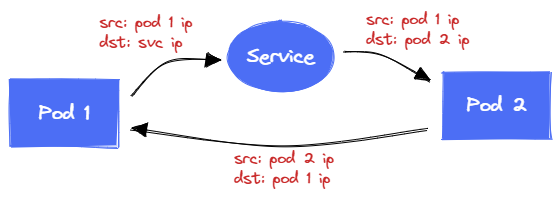
通常,Pod 都是通过 Service Domain 来访问 Service 的,因此在向 Service IP 发送请求之前,Pod 先需要访问 DNS Server 进行一次域名解析(DNS Server 地址配置在容器环境中的 /etc/resolv.conf 文件。
下文中不会提到 DNS 解析,其就是一次 Pod 向 Service IP 发送请求的过程。
Service 资源的相关概念见 Kubernetes - Service 与 Endpoint,下面主要介绍 Service 的实现。
Service 是一个虚拟的概念,
目前,kube-proxy 支持使用三种方式实现 Service:
-
userspace (deprecated)
Pod 发出的所有数据包都由 kube-proxy 进程接收,kube-proxy 解析包后将其进行转发到 Service 后端的 Pod。
-
iptables (default)
kube-proxy 进程仅仅负责配置 iptables,数据包经过 iptables 时被转发到 Service 后端的 Pod。
-
ipvs
kube-proxy 进程负责配置 IPVS 规则,数据包经过 IPVS 时被赚翻到 Service 后端的 Pod。
4.1 userspace 模式
在 userspace 模式下,kube-proxy 负责:
-
数据包转发
对于每个 Service,kube-proxy 会在 Node 打开对应的一个端口(随机选择)。任何发送到该端口的请求,都会被 kube-proxy 接收,并转发到 Service 后端的某个 Pod(通过 Endpoints 查询后端 Pod)。
-
配置 iptables
为了能捕获让 Pod 发送给 Service 的请求,kube-proxy 会配置 iptables,使得任何发送给 Service IP/Port 请求会被转发到 kube-proxy 打开的端口。
当 Pod 向 Service IP + Port 发送请求时,iptables 将其转发到同 Node 的 kube-proxy 进程处理,kube-proxy 解析并将其转发给 Service 后端的 Pod。
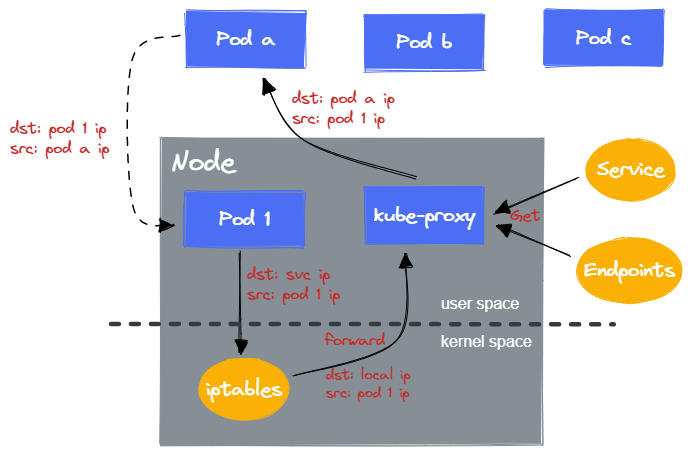
可以看到,数据包需要经过 iptables 的转发以及 kube-proxy 进程的处理。也就是说,需要进行一次额外的内核态与用户态的转换来处理数据包。这也就导致了 userspace 模式的性能低下,使得其被废弃。
4.2 iptables 模式
在 iptables 模式下,kube-proxy 负责:
-
配置 iptables
为了让发送给 Service 的请求转发后后端的 Pod,kube-proxy 会配置 iptables。
kube-proxy 会 Watch Service 与 Endpoints 对象,同步地更新 iptables。
当 Pod 向 Service IP + Port 发送请求时,由于 kube-proxy 的配置,iptables 会直接将数据包转发到 Service 后端的 Pod。
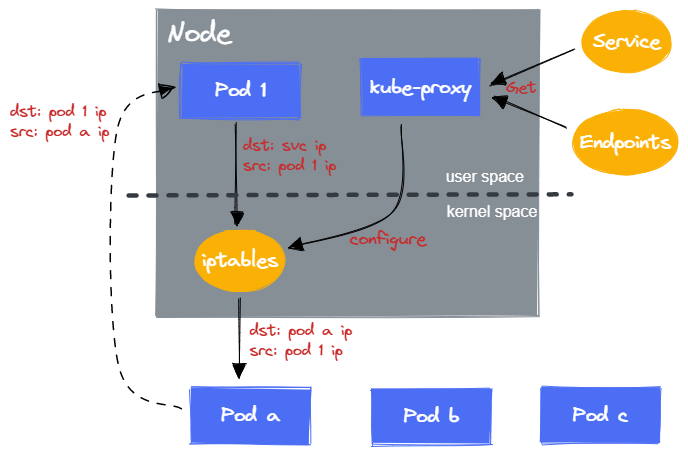
可以看到,由于 iptables 负责处理数据包,就不需要额外的内核态与用户态的切换了。
不过,在大量 Service 的情况下,iptables 会有着许多的转发规则,导致转发性能的下降。并且 iptables 的每一次配置都是全量的更新,也会有性能的消耗。这也是 iptables 自身实现的问题。
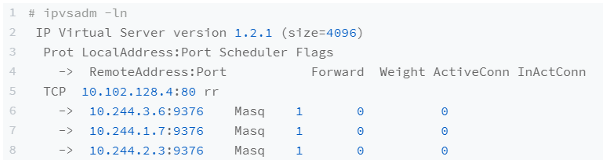
4.3 IPVS 模式
在 IPVS 模式下,kube-proxy 负责:
-
创建虚拟网卡
对于每一个 Service,kube-proxy 会在 Node 上创建对应的虚拟网卡,并分配 Service IP 作为 IP 地址。

-
配置 IPVS
对于 Service 后端的所有 Pod,kube-proxy 会在虚拟网卡上配置 IPVS 规则,使得所有后端的 Pod IP 作为 IPVS 虚拟主机。同时设置转发策略。

当 Pod 向 Service IP + Port 发送请求时,数据包会由 Node 上的虚拟网卡处理,而 IPVS 的配置使得数据包会被转发到 Service 后端的 Pod。
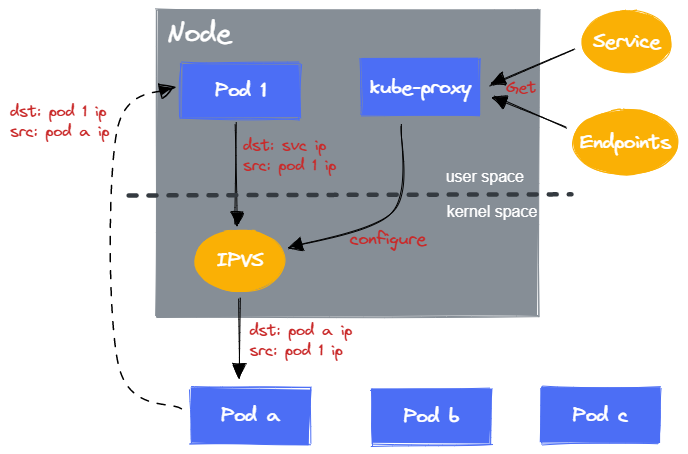
IPVS 也是使用的 Linux netfilter 模块实现的。但是对比 iptables 的链式调用,IPVS 底层使用 hash map 来进行数据包的路由,因此性能更高。
5 NetworkPolicy
Kubernetes 中 Pod 之间的网络默认是完全连通的,每个 Pod 可以向任何 Pod 发送请求,也可以接收任何 Pod 的请求。
如果要对 Pod 之间的网络进行隔离,可以使用 NetworkPolicy 对象。
目前,NetworkPolicy 还有着许多的限制:
- 强制流量进入公共的 Gateway(通过 Service Mesh 实现)
- 基于 Node 配置策略(可以使用 CIDR 配置)
- 适用于所有 Namespace 或 Pod 的策略
- 生成网络安全事件日志的能力(例如,哪些连接被拒绝)
- 显式拒绝策略的能力(NetworkPolicy 只能添加允许策略)
- 禁止 Localhost 或来自 Node 的网络流量(Pod 无法阻塞访问 Localhost,以及无法拒绝来自本地 Node 的访问)
5.1 NetworkPolicy 定义
Pod 的网络隔离分为:Ingress 与 Egress 隔离。这两种隔离设置都是独立的,并且只关乎于 Pod 与另一个 Pod 的访问。
-
Egress 隔离
默认情况下,一个 Pod 的 Egress 是非隔离的,所有外向流量都是允许的。当应用了任意的 Egress 策略时,那么只有策略允许的流量才能通过,默认的策略变为拒绝。
多个 NetworkPolicy 的 Egress 的效果是相加的。
-
Ingress 隔离
默认情况下,一个 Pod 的 Ingress 是非隔离的,即所有入站流量都是允许的。当应用了任意的 Ingress 策略时,那么只有策略允许的流量才能通过,默认的策略变为拒绝。
要允许源 Pod 到目标 Pod 的连接,源 Pod 的 Egress 策略与目标 Pod 的 Ingress 策略都需要允许。
|
|
- podSelector - 筛选应用该 NetworkPolicy 的 Pod;
- policyTypes - 应用 Ingress 还是 Egress;
- ingress - 设置的 Ingress 策略
- egress - 设置的 Egress 策略
5.2 To 和 From
Ingress 的 from 与 Egress 的 to 都可以指定四种 Selector:
- podSelector - 与 NetworkPolicy 同 Namespace 下,通过 Label 筛选出允许的 Pod;
- namespaceSelector - 选择特定的 Namespace 下的所有 Pod;
- podSelector + namespaceSelector - 筛选特定 Namespace 下的特定 Pod;
- ipBlock - 基于 IP Range 筛选,IP 可能来自于 Pod 或 LB 等;
5.3 针对特定 Port
通过 ports 可以针对特定端口范围进行限制:
|
|
5.4 firewall 插件
NetworkPolicy 功能的实现是由 CNI Plugin 实现的,因此不同的 CNI Plugin 可能有着不同的实现。
不过 Kubernetes 提供了一个通用的 CNI Chained Plugin firewall,支持配置 iptables 与 firewalld 来限制 Container 的出入流量。因此 CNI Plugin 可以使用该 Plugin 来实现 NetworkPolicy 功能。
以 iptables 为例,其实现就是通过配置 iptables 来允许或拒绝数据包。