总结系列的文章是自己的学习或使用后,对相关知识的一个总结,用于后续可以快速复习与回顾。
本文是对自己使用过的 docker 使用的网络模式的原理的总结。
1 概览
docker 容器网络目前包含 5 中模式,包括:
bridge:默认的网络模式,使用 bridge 虚拟网卡 + iptables 实现一个内地内网,所有容器都处于该内网内,并且可以相互访问;host:与宿主机处于同一个 net namespace,使用宿主机网络环境;overlay:在多个 docker daemon 之间建立 overlay 网络,使得不同 docker daemon 的容器之间可以相互通信;macvlan:使用 macvlan 虚拟网卡,将容器物理地址暴露在宿主机局域网中,你可以认为就是一台同局域网的物理机;none:不进行任何网络配置,通常与自定义网络 driver 配合使用;
除了上述模式之外,每个容器也可以加入其它容器的网络中(通过加入对应的 net namespace)。
docker 还支持使用自定义的网络插件,这块不了解,具体见官方文档。
下面所有示例都在虚拟机 ubuntu 20.04 与内核 5.4.0-52-generic 中完成,docker 版本如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
$docker version
Client:
Version: 19.03.8
API version: 1.40
Go version: go1.13.8
Git commit: afacb8b7f0
Built: Wed Oct 14 19:43:43 2020
OS/Arch: linux/amd64
Experimental: false
Server:
Engine:
Version: 19.03.8
API version: 1.40 (minimum version 1.12)
Go version: go1.13.8
Git commit: afacb8b7f0
Built: Wed Oct 14 16:41:21 2020
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.3.3-0ubuntu2
GitCommit:
runc:
Version: spec: 1.0.1-dev
GitCommit:
docker-init:
Version: 0.18.0
GitCommit:
|
2 背景知识
2.1 cgroup 与 namespace
这部分网上知识很多,这里就不复制别人的了。
2.2 docker 如何使用 net namespace
namespace 用于各个进程间的环境的隔离,而容器运行(非 host 与 container 模式)的就是处于一个独立的 net namespace。
当处于一个 net namespace 时,可以认为,内核协议栈、iptables(net_filter)、网络设备等与其他 net namespace 都是隔离的。(这里只是说可以这么认为,但是真正还是只有一个内核,内核为 namespace 做了逻辑上的隔离)
在容器运行之间,docker 就会创建容器对应的 net namespace,并构建好对应的网络,然后将其 ‘持久化’(因为默认 namespace 是随着进程消失而消失的,如果想进程消失而 namespace 存在,那么需要将其 mount 到一个文件上)。
例如,当我们创建了一个容器后,可以看到这么一个挂载:
1
2
3
|
$ mount
…
nsfs on /run/docker/netns/9779108cb6b0 type nsfs (rw)
|
该文件就是对应 net namespace 的挂载,通过对比容器进程的 netns inode 与 文件 inode 可以证明:
1
2
3
4
5
6
7
8
9
10
|
$ docker top br0_container
UID PID PPID C STIME TTY TIME CMD
root 92658 92640 0 Nov06 pts/0 00:00:00 /bin/bash
$ ls -lhi /proc/92658/ns/net
474863 lrwxrwxrwx 1 root root 0 Nov 7 12:42 /proc/92658/ns/net -> 'net:[4026532287]'
# 文件 inode 与进程 net 指向 inode 相同
$ ls -lhi /run/docker/netns/9779108cb6b0
4026532287 -r--r--r-- 1 root root 0 Nov 6 19:47 /run/docker/netns/9779108cb6b0
|
在容器被删除后,对应 net namespace 就会被销毁。
而各个网络模式最大的不同,就是在于 namespace 创建后,对应的 “构建网络” 的操作了。
2.3 bridge 虚拟网络设备
bridge 网络设备 相当于一个 “交换机”,让任何其他网络设备链接上 bridge 时,所有包的都会无条件经过 bridge 转发,而链接的网络设备就变成了一根 “网线”。
不过与真实的交换机不同,brdige 网卡可以被赋值 IP,当 bridge 拥有 IP 后,它就与内核协议栈连接了,因此接收到的包可以到达内核协议栈的 IP 层处理,也就会经过 net_filter 处理。
2.4 veth-pair 虚拟网络设备
veth-pair 设备 总是成对的出现,当数据包进入一端 veth 设备时,会从另一端 veth 设备出。veth-pair 两个设备可以处于不同的 net namespace,也就可以实现不同 net namespace 间数据传输。
默认下,veth 设备链接的两端是内核协议栈。不过 veth 设备链接上 bridge,这样另一端发送的数据都会由 bridge 处理。
2.5 macvlan 虚拟网络设备
macvlan 网络设备 可以有 mac 地址与 ip 地址,用于将 net namespace 连接到宿主机的物理网络中,相当于,容器直接连接着物理网络。
macvlan 网络设备有着多种的模式,包括:bridge、private 等,这影响着各个 macvlan 网络设备之间的通信。
更多 macvlan 网络设备推荐文章:Linux interfaces for virtual networking
3 Bridge 网络
3.1 创建/删除 Bridge 网络
(1) 创建网络
先试着创建一个自定义的 bridge 网络,观察 docker 会对应创建哪些东西。
1
2
3
4
5
6
7
|
$ docker network create --driver=bridge \
--subnet=192.168.100.0/24 \
--ip-range=192.168.100.0/26 \
--gateway=192.168.100.1 \
--opt com.docker.network.bridge.name=mybr0 \
mybridge0
2e61a7dc333c1bc61d9cb86503ce4cd5a7435977ea2f9b7cc97fc71ae0e2bb93
|
--driver=bridge 指定创建的网络 driver;--subnet=192.168.100.0/24 指定对应 bridge 网络的网段;--ip-range=192.168.100.0/26 指定运行分配给容器的 ip 范围,当然,这个是要在指定的网段内的;--gateway=192.168.100.1 指定该内网的网关 IP;--opt com.docker.network.bridge.name=mybr0 指定创建虚拟 bridge 网卡的命名;mybridge0 为创建的 docker network 的命名;
通过 ifconfig 可以看到,bridge 网络创建会对应创建一个 bridge 网络设备,作为整个内网的 ‘交换机’。其 IP 就是指定的 gateway IP。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
$ ifconfig
…
mybr0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500
inet 192.168.100.1 netmask 255.255.255.0 broadcast 192.168.100.255
ether 02:42:46:8a:cf:34 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
…
$ brctl show
bridge name bridge id STP enabled interfaces
mybr0 8000.0242efdb0984 no
|
但是与虚拟机网络中的 bridge 网卡不同,该 bridge 不会连接任何的物理网卡,仅仅是作为内网的 ‘交换机’ 使用。但是,毕竟内网是虚拟的,没有实际与物理网络连接,如何访问外网呢?
答案是,通过内核 iptables 进行 NAT,然后将包从实际的物理网卡上发送与接受。因此还有一部分的改变在于 iptables,主要会建立的是 nat 与 filter 表的规则。
先看 nat 表的相关规则(下面输出中省略了不相关规则):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
$ iptables -t nat -L -nv
Chain PREROUTING (policy ACCEPT 2 packets, 88 bytes)
target prot opt in out source destination
DOCKER all -- * * 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL
Chain INPUT (policy ACCEPT 2 packets, 88 bytes)
target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 124 packets, 8797 bytes)
target prot opt in out source destination
DOCKER all -- * * 0.0.0.0/0 !127.0.0.0/8 ADDRTYPE match dst-type LOCAL
Chain POSTROUTING (policy ACCEPT 124 packets, 8797 bytes)
target prot opt in out source destination
MASQUERADE all -- * !mybr0 192.168.100.0/24 0.0.0.0/0
Chain DOCKER (2 references)
target prot opt in out source destination
RETURN all -- mybr0 * 0.0.0.0/0 0.0.0.0/0
|
-
PREROUTING 与 OUTPUT 链中规则,使得所有入和出的包都会经过 DOCKER 链;
-
POSTROUTING 链中,将 mybridge0 网络(192.168.100.0/24)的内网 ip 通过 MASQUERADE 行为进行伪装(可以简单认为内网 ip 会变为当前网卡的 ip);
当然,如果包发往的是 mybr0 网卡,说明是 mybridge0 网络内部通信,就不需要进行 MASQUERADE 伪装(!mybr0);
当容器发包时,会通过 mybr0 网卡转发进入内核栈,因此在 filter 表中,相关的规则都是针对于 “in=mybr0”。看一下 filter 表的规则:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
$ iptables -t filter -L -nv
Chain INPUT (policy ACCEPT 61774 packets, 79M bytes)
Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
target prot opt in out source destination
DOCKER-USER all -- * * 0.0.0.0/0 0.0.0.0/0
DOCKER-ISOLATION-STAGE-1 all -- * * 0.0.0.0/0 0.0.0.0/0
ACCEPT all -- * mybr0 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED
DOCKER all -- * mybr0 0.0.0.0/0 0.0.0.0/0
ACCEPT all -- mybr0 !mybr0 0.0.0.0/0 0.0.0.0/0
ACCEPT all -- mybr0 mybr0 0.0.0.0/0 0.0.0.0/0
Chain OUTPUT (policy ACCEPT 42290 packets, 55M bytes)
target prot opt in out source destination
Chain DOCKER (2 references)
target prot opt in out source destination
Chain DOCKER-ISOLATION-STAGE-1 (1 references)
target prot opt in out source destination
DOCKER-ISOLATION-STAGE-2 all -- mybr0 !mybr0 0.0.0.0/0 0.0.0.0/0
RETURN all -- * * 0.0.0.0/0 0.0.0.0/0
Chain DOCKER-ISOLATION-STAGE-2 (2 references)
target prot opt in out source destination
DROP all -- * mybr0 0.0.0.0/0 0.0.0.0/0
RETURN all -- * * 0.0.0.0/0 0.0.0.0/0
Chain DOCKER-USER (1 references)
target prot opt in out source destination
RETURN all -- * * 0.0.0.0/0 0.0.0.0/0
|
- FORWARD -> DOCKER-ISOLATION-STAGE-1 -> DOCKER-ISOLATION-STAGE-2 表明允许包从 mybr0 进入并转发(即容器可以向外正常发包);
- FORWARD 中对 mybr0 进入的包设置了 conntrack,使得能够收到连接建立后的正常的回包;
(2) 删除网络
通过 docker network remove 删除网络时,会发现对应的 bridge 网卡与 iptables 规则都被删除。
1
2
|
$ docker network remove 5a17670afb6f
5a17670afb6f
|
3.2 启动容器后的网络
下面看下容器启停后,带来的网络变化。先启动最简单的一个容器,指定使用网络为上面创建的 mybridge0。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
$ docker run -dt --rm --network=mybridge0 --name br0_container ubuntu
676f7f9eab12a20fb3a975fa99cc2c92433a9581b5774ea58e63d447d86aa5ad
$ docker inspect 676f7f9eab12
…
"Networks": {
"mybridge0": {
"IPAMConfig": null,
"Links": null,
"Aliases": [
"882cac3e472f"
],
"NetworkID": "af1dbf619ac62be1ad8a6b63696d3e6edff77cceab6cd0ee78de4b51e0d33683",
"EndpointID": "56cd85c5121d7d14146fcacc75599f6c56034e758e81f405a51437276ac6ac9f",
"Gateway": "192.168.100.1",
"IPAddress": "192.168.100.2",
"IPPrefixLen": 24,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"MacAddress": "02:42:c0:a8:64:02",
"DriverOpts": null
}
}
…
|
--network=mybridge0 表明以 mybridge0 网络启动容器;- 观察容器具体参数,可以看到,容器被随机分配 mybridge0 设置的 ip-range 一个 ip,并且 gateway 就是 mybridge0 网络的网关地址;
观察网络设备,可以看到一个 veth-pair 设备 出现在宿主机上,并且连接到了 mybr0 网卡:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
$ ifconfig
…
vethef6b174: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet6 fe80::e8ad:86ff:fefe:14ca prefixlen 64 scopeid 0x20<link>
ether ea:ad:86:fe:14:ca txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 23 bytes 1882 (1.8 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
…
$ brctl show
bridge name bridge id STP enabled interfaces
mybr0 8000.0242efdb0984 no vethef6b174
|
veth-pair 都是成对出现的,可以简单被看做一个通道,一端发入的包会从另一端发出,并进入内核协议栈。不过,在 bridge 网络环境下,veth5b480f8 连接到 mybr0,所以所有从 veth5b480f8 发出的包都会被 mybr0 接手转发(相当于就是一根网线插入了交换机)。
可以进入容器 namespace,看一下容器内的 veth 设备。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
$ docker exec -it br0_container bash
# 以下在容器 namesapce 环境执行
root@676f7f9eab12:/# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.100.2 netmask 255.255.255.0 broadcast 192.168.100.255
ether 02:42:c0:a8:64:02 txqueuelen 0 (Ethernet)
RX packets 1928 bytes 21609413 (21.6 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1817 bytes 102779 (102.7 KB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
root@676f7f9eab12:/sys/class/net/eth0# ethtool -i eth0
driver: veth
version: 1.0
firmware-version:
expansion-rom-version:
bus-info:
supports-statistics: yes
supports-test: no
supports-eeprom-access: no
supports-register-dump: no
supports-priv-flags: no
root@676f7f9eab12:~# cat /sys/class/net/eth0/iflink
15
|
- 在容器内的仅仅有一个 eth0 网卡,ip 设置为了容器的 ip。但是其实这个网卡就是 veth 设备改了名字;
- 通过
ethtool -i eth0 命令看到,其对应 driver 是 veth,并且 /sys/class/net/eth0/iflink 文件表明了对端的 veth 网卡编号为 15(即宿主机看到的 veth 网卡设备);
现在,我们试着启动容器并添加一个 tcp 端口映射。
1
2
3
4
|
$ docker run -dt --rm \
--network=mybridge0 --publish 12211:8080 \
--name br0_container ubuntu
2502f7397a37e2ab482f8a9152d1ed968dd2e2825c71eb2a6737e4900f7236c1
|
而这个端口映射,就是将宿主机的 12211 端口映射给容器的 8080,所以所有发往宿主机的 12211 端口的包,都会被修改端口并转发到容器内部。这也是通过 iptables 实现的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
iptables -t nat -L -nv
Chain PREROUTING (policy ACCEPT 0 packets, 0 bytes)
target prot opt in out source destination
DOCKER all -- * * 0.0.0.0/0 0.0.0.0/0 ADDRTYPE match dst-type LOCAL
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
target prot opt in out source destination
Chain OUTPUT (policy ACCEPT 0 packets, 0 bytes)
target prot opt in out source destination
DOCKER all -- * * 0.0.0.0/0 !127.0.0.0/8 ADDRTYPE match dst-type LOCAL
Chain POSTROUTING (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
10 617 MASQUERADE all -- * !mybr0 192.168.100.0/24 0.0.0.0/0
0 0 MASQUERADE tcp -- * * 192.168.100.2 192.168.100.2 tcp dpt:8080
Chain DOCKER (2 references)
pkts bytes target prot opt in out source destination
0 0 RETURN all -- mybr0 * 0.0.0.0/0 0.0.0.0/0
0 0 DNAT tcp -- !mybr0 * 0.0.0.0/0 0.0.0.0/0 tcp dpt:12211 to:192.168.100.2:8080
|
- PREROUTING -> DOCKER 链中,所有不是从 mybr0 进入的包,并且发往 tcp 12211 端口的包,都会被 DNAT 为发往 192.168.100.2:8080。这样就实现了端口映射的功能。
3.3 bridge 网络总结
中心思想:bridge 网络使用 bridge 网卡创建了一个本地的内网,而 bridge 网卡 + iptables 规则成为了这个内网的 ‘路由器'。其中:
- bridge 网卡作为二层的交换机,bridge 网卡 ip 作为路由器的网关 ip。
- iptables 规则实现了 brdige 网卡与物理网络的连接
- 宿主机内核栈实现了这个 ‘路由器’ 的路由功能。
下图展示了整个 bridge 网络的模型(图片来自网络):
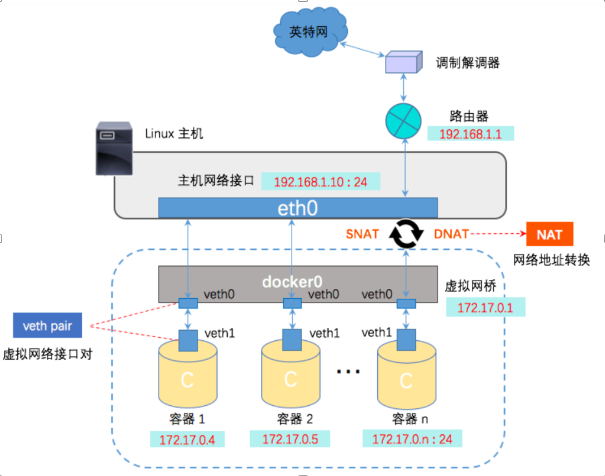
其中比较关键的点:
- veth pair 设备将容器 net namespace 连接到 bridge 网卡(可以看做将 veth pair 作为网线插到了 bridge 这个 ‘路由器’ 上)。
- iptables 实现了 bridge 网卡与物理网络的 ‘连接’。
bridge 网卡收到的包,经过 iptables 的 MASQUERADE 将包进行地址转换,并经过内核协议栈的路由通过物理网卡发送到物理网络。而回包通过 conntrack 机制正常接收与逆地址转换。
- 容器与宿主机的端口映射,也是通过 iptables 的 DNAT 实现的。
4 Host 网络
Host 网络没啥好说的,启动容器不创建新的 namespace,依旧在宿主机的 net namespace 下。
1
2
|
$ docker run -dt --rm --network=host --name host_container ubuntu
da1c426a7c7501b329258b12cb475ff42669837ca686d6e946511632461cc946
|
观察 mount,可以看到对应还是有 net namespace 的文件挂载,文件名为 default:
1
2
3
|
$ mount
…
nsfs on /run/docker/netns/default type nsfs (rw)
|
文件 inode 对比当前宿主机 net namespace inode,是一致的:
1
2
3
4
|
$ ls -lh /proc/self/ns/net
lrwxrwxrwx 1 root root 0 Nov 7 14:47 /proc/self/ns/net -> 'net:[4026531992]'
$ ls -lhi /run/docker/netns/default
4026531992 -r--r--r-- 1 root root 0 Oct 30 16:50 /run/docker/netns/default
|
5 macvlan 网络
macvlan 网络使用 macvlan 虚拟网络设备,将容器 net namespace 网络暴露在与当前宿主机同级的局域网内,相当于容器就是当前网络内的一台 “主机”。
macvlan 网络设备也包括多种模式:bridge mode、802.1q trunk bridge mode。下面示例都是基于普通的 brdige mode。
因为 macvlan 网络在虚拟机网络下不太好验证,所以下面例子来自于一台物理机上。
5.1 创建/删除 macvlan 网络
通过 docker network create 创建 macvlan 网络。
1
2
3
4
|
$ docker network create -d macvlan \
--subnet=192.168.67.130/24 --gateway=192.168.67.1 \
-o parent=eth0 mymacvlan0
633aae3d4f430352e5439e2650c02fe9c2092b99b5b8252f8141fa5d62ec7e70
|
-d macvlan,指定 macvlan 网络-subnet=192.168.67.130/24,因为 macvlan 网络下的容器会直接连入物理网络,所以子网也是要在当前子网内;--gateway=192.168.67.1,同样,gateway 就是宿主机的网关地址;-o parent=eth0,指定 macvlan 设备链接的物理网卡,一定要是一个真正可联网的物理网卡;
不过与 bridge 网络不同的是,创建一个 macvlan 网络仅仅是记录其对应的配置,不会创建对应的 macvlan 网卡或者 iptables 规则。因为 macvlan 网卡是与 net namespace 绑定的,所以当创建 net namespace 时才会出现对应网络设备。
5.2 启停容器后的网络
1
2
3
4
5
|
$ docker run --net=mymacvlan0 \
-dt --rm --name macvlan_container \
--ip=192.168.67.139 --privileged \
centos_ctr bash
2eff4835733734b6819c7f97ae41585985d95c1ea4c66a6a478a43e71b60b6d6
|
启动容器,如果不指定 IP,Docker 会在配置的网段里分配一个。
tip
为了能够方便排查网络问题,使用的容器镜像 centos_ctr 是由 centos 镜像以 host 网络启动,预装一些命令后,才由容器导出的镜像。
但是发现进入容器后,发现静态配置 IP 无法 ping 通网关(宿主机是正常无法 ping 通,因为内核会丢弃 macvlan 网卡的包)。研究后不清楚具体原因,但是这台宿主机接的是交换机,不知道是不是不是路由器导致的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
$ docker exec -it macvlan_container bash
# 以下是容器中命令
[root@2eff48357337 /]# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.67.139 netmask 255.255.255.0 broadcast 192.168.67.255
ether 02:42:c0:a8:43:8b txqueuelen 0 (Ethernet)
RX packets 433282 bytes 27463954 (26.1 MiB)
RX errors 0 dropped 26809 overruns 0 frame 0
TX packets 91342 bytes 6649728 (6.3 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@2eff48357337 /]# ping 192.168.67.1
PING 192.168.67.1 (192.168.67.1) 56(84) bytes of data.
From 192.168.67.139 icmp_seq=1 Destination Host Unreachable
From 192.168.67.139 icmp_seq=2 Destination Host Unreachable
|
因此,换个思路,静态 IP 不行,就通过 DHCP 获取一个 IP 尝试是否能够连通网络。
在删除静态 IP 之后,调用 dhclient 从上层路由器获取一个 IP。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
# 删除 eth0 网卡 IP
[root@2eff48357337 /]# ip address del 192.168.67.139 dev eth0
Warning: Executing wildcard deletion to stay compatible with old scripts.
Explicitly specify the prefix length (192.168.67.139/32) to avoid this warning.
This special behaviour is likely to disappear in further releases,
fix your scripts!
[root@2eff48357337 /]# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
ether 02:42:c0:a8:43:8b txqueuelen 0 (Ethernet)
RX packets 435540 bytes 27608133 (26.3 MiB)
RX errors 0 dropped 26983 overruns 0 frame 0
TX packets 91763 bytes 6678670 (6.3 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# 调用 dhclient 获取新的 IP
[root@2eff48357337 /]# dhclient -r && dhclient -v
Removed stale PID file
Internet Systems Consortium DHCP Client 4.3.6
Copyright 2004-2017 Internet Systems Consortium.
All rights reserved.
For info, please visit https://www.isc.org/software/dhcp/
Listening on LPF/eth0/02:42:c0:a8:43:8b
Sending on LPF/eth0/02:42:c0:a8:43:8b
Sending on Socket/fallback
DHCPDISCOVER on eth0 to 255.255.255.255 port 67 interval 3 (xid=0xdf4e0e25)
DHCPREQUEST on eth0 to 255.255.255.255 port 67 (xid=0xdf4e0e25)
DHCPOFFER from 192.168.9.253
DHCPACK from 192.168.9.253 (xid=0xdf4e0e25)
System has not been booted with systemd as init system (PID 1). Can't operate.
Failed to create bus connection: Host is down
bound to 192.168.9.235 -- renewal in 38783 seconds.
[root@2eff48357337 /]# ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.9.235 netmask 255.255.255.0 broadcast 192.168.9.255
ether 02:42:c0:a8:43:8b txqueuelen 0 (Ethernet)
RX packets 435635 bytes 27614880 (26.3 MiB)
RX errors 0 dropped 27001 overruns 0 frame 0
TX packets 91767 bytes 6679438 (6.3 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@2eff48357337 /]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.9.253 0.0.0.0 UG 0 0 0 eth0
192.168.9.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
|
可以看到,DHCP 获得的 IP 与宿主机都不是同一个网段的,并且网关地址也不是同一个,因此上层连着交换机有多个网段(这块不太理解了)。
但是,测试后是可以 ping 通网关,并且可以访问外网的:
1
2
3
4
|
[root@2eff48357337 /]# ping 192.168.9.253
PING 192.168.9.253 (192.168.9.253) 56(84) bytes of data.
64 bytes from 192.168.9.253: icmp_seq=1 ttl=64 time=0.637 ms
64 bytes from 192.168.9.253: icmp_seq=2 ttl=64 time=0.250 ms
|
5.3 总结
中心思想:将 macvlan 网络启动容器看做一个与宿主机同级的网络,其获取 IP 方式都与正常的机器相同。
参考